Train encoder models on Simplismart for sequence classification tasks, enabling efficient feature extraction and accurate prediction from textual data.
Encoder models are ideal for tasks like sentiment analysis, spam detection, intent classification, and other text categorization problems.
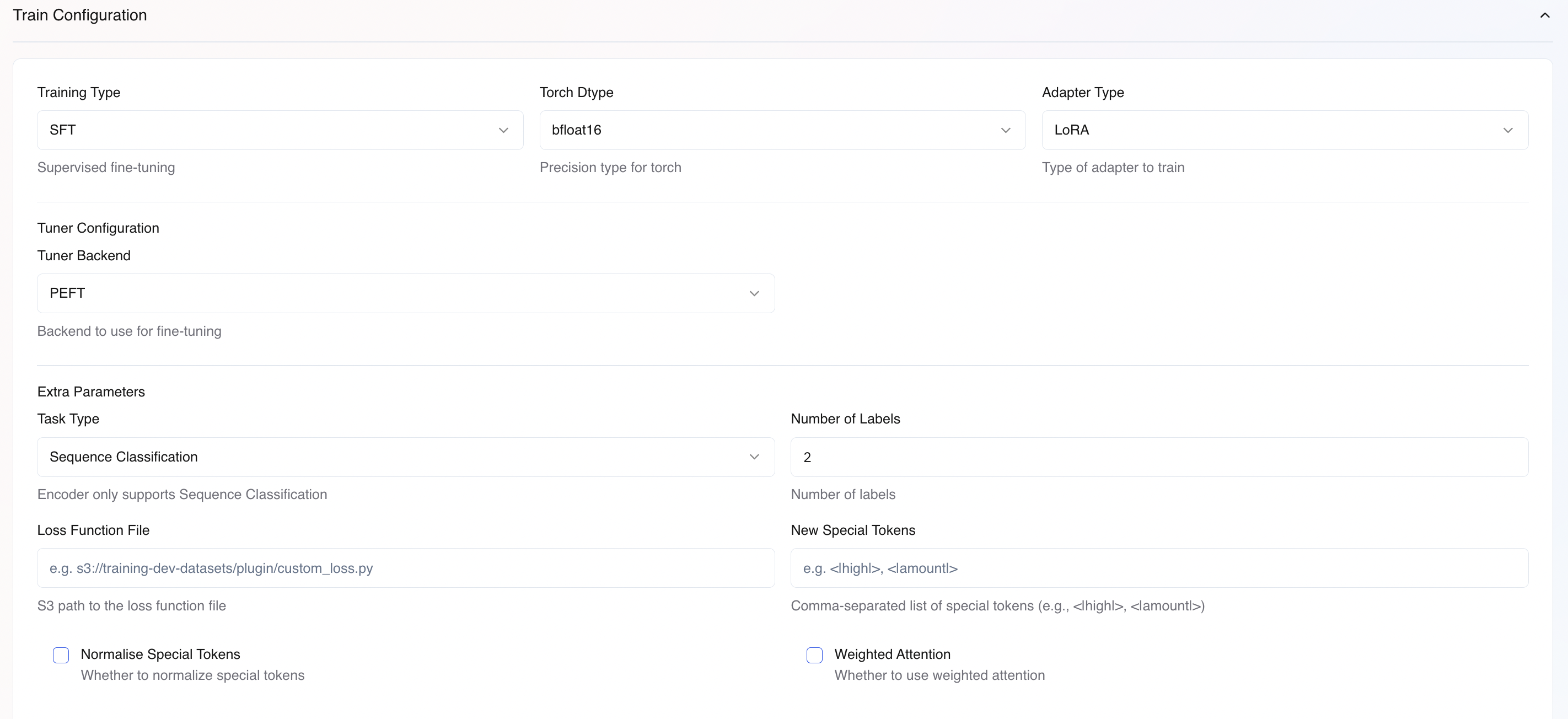
Defines the model’s objective. For encoder training, use Sequence Classification.
Sequence Classification
Number of Labels
Total number of classes in your dataset (e.g., 2 for binary classification, 5 for 5-class).
-
Loss Function File
S3 path to a custom loss function file (e.g., s3://bucket/loss_function.py). Must expose loss_fn_adapter variable.
-
New Special Tokens
Comma-separated list of special tokens to add to the tokenizer
-
Normalize Special Tokens
Whether to aggregate embeddings of compound special tokens from their constituent tokens.
False
Weighted Attention
Uses attention pooling to create a weighted representation of input tokens instead of relying on the [CLS] token.
False
Special Token Initialization:Normalisation of embedding is only performed when Normalize Special Tokens is True.When using compound special tokens (e.g., <|high_amount|>), their embeddings can be initialized from constituent tokens (<|high|> and <|amount|>) by taking the normalized mean of the constituent embeddings. This helps the model understand the semantic relationship between tokens.Example:If you add tokens <|high|>, <|amount|>, and <|high_amount|>, the embedding for <|high_amount|> will be:embedding(<|high_amount|>) = (embedding(<|high|>) + embedding(<|amount|>)) / 2
The custom loss function must expose a variable named loss_fn_adapter (a Callable) with the signature shown above. The function receives model outputs, labels, and optionally the number of items in batch, and must return a scalar loss tensor.
Show Weighted Attention Pooling Example
Weighted attention pooling computes a learned attention score for each token in the sequence, creating a weighted representation that focuses on the most informative tokens. This approach can be more effective than relying solely on the [CLS] token for sequence classification tasks.
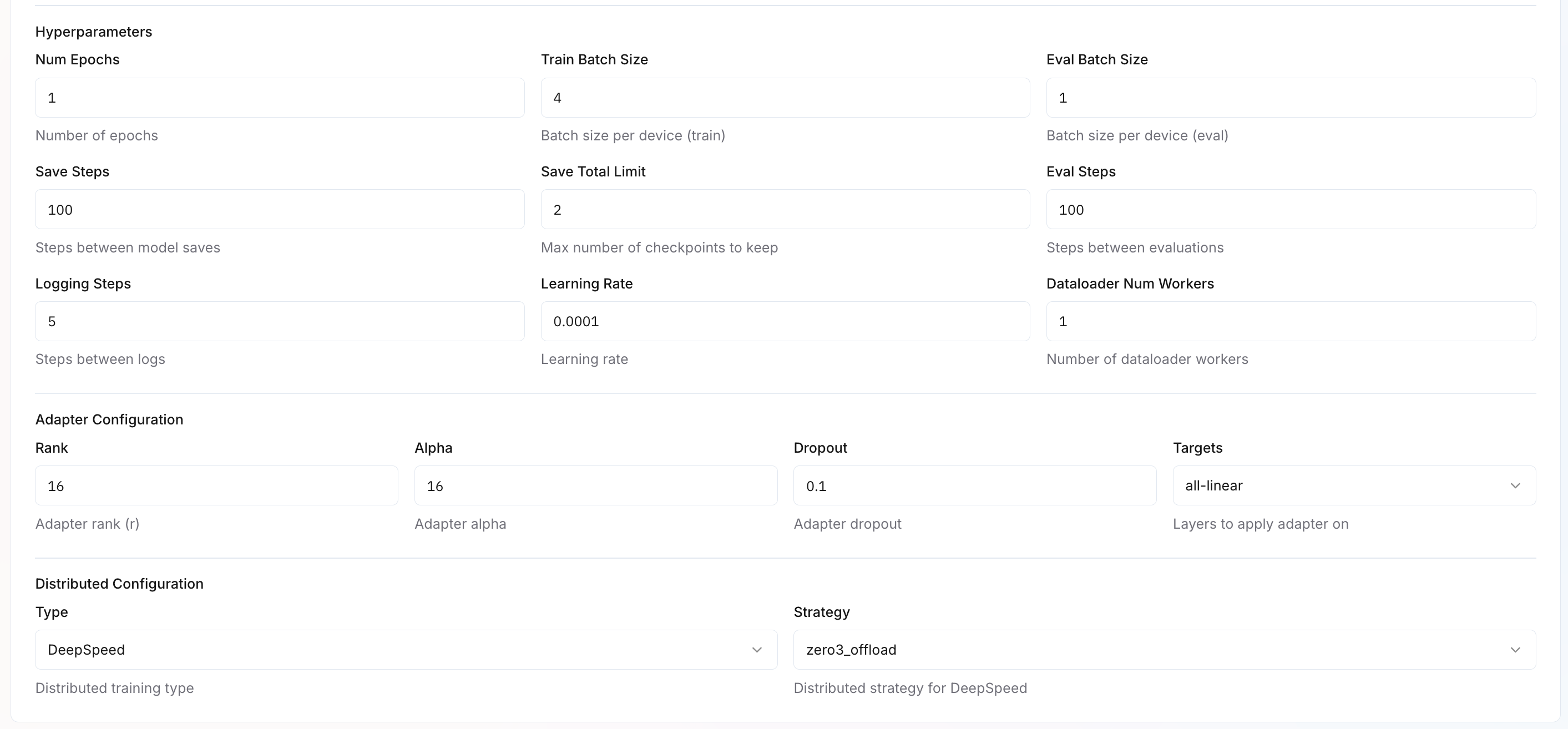
Configure fine-tuning parameters based on your selected Adapter Type (LoRA or Full). Different parameters apply depending on your choice. Learn more about adapter configuration.
Parameter
Description
Default Value
Applies To
Rank (r)
Adapter rank determines capacity. Higher rank = more expressive but slower. 16-64 works for most tasks.
16
LoRA only
Alpha
Scaling factor for adapter updates. Typically set equal to rank. Higher alpha = stronger influence.
16
LoRA only
Dropout
Regularization to prevent overfitting. Randomly drops adapter weights during training.
0.1
LoRA & Full
Targets
Which model layers to fine-tune. all-linear targets all linear/attention layers for maximum adaptation.
Once training completes successfully, you can compile and deploy your Encoder model for inference.
During model compilation, if your usecase is text-classification please add a field under extra_params adding "task": "text-classification".Sharing below, a sample Pipeline Configuration for your reference. By default, it takes fill-mask as a task.
For encoder models, once deployed, you can run inferences using the example given below. Your request payload and expected output will change according to your use-case.
import requestsurl = "YOUR_MODEL_ENDPOINT"data = { "text": "The capital of France is Paris"}headers = { "Authorization": "Bearer <api-key>"}response = requests.post(url, json=data, headers=headers)print(response.json())
You can refer to the HuggingFace page of the respective model for more information about the<MASK>token.
import requestsurl = "YOUR_MODEL_ENDPOINT"data = { "text": "The capital of France is [MASK]."}headers = { "Authorization": "Bearer <api-key>"}response = requests.post(url, json=data, headers=headers)print(response.json())
For RoBERTa base model replace [MASK] with <mask>
Expected Output
[ {'score': 0.9036276936531067, 'token': 2201, 'token_str': ' Paris', 'sequence': 'The capital of France is Paris.' }, {'score': 0.08029197156429291, 'token': 12790, 'token_str': ' Lyon', 'sequence': 'The capital of France is Lyon.' }, {'score': 0.004803310614079237, 'token': 16911, 'token_str': ' Nice', 'sequence': 'The capital of France is Nice.' }, {'score': 0.002099075587466359, 'token': 8239, 'token_str': ' Nancy', 'sequence': 'The capital of France is Nancy.' }, {'score': 0.0011299046454951167, 'token': 35767, 'token_str': ' Napoleon', 'sequence': 'The capital of France is Napoleon.' }]
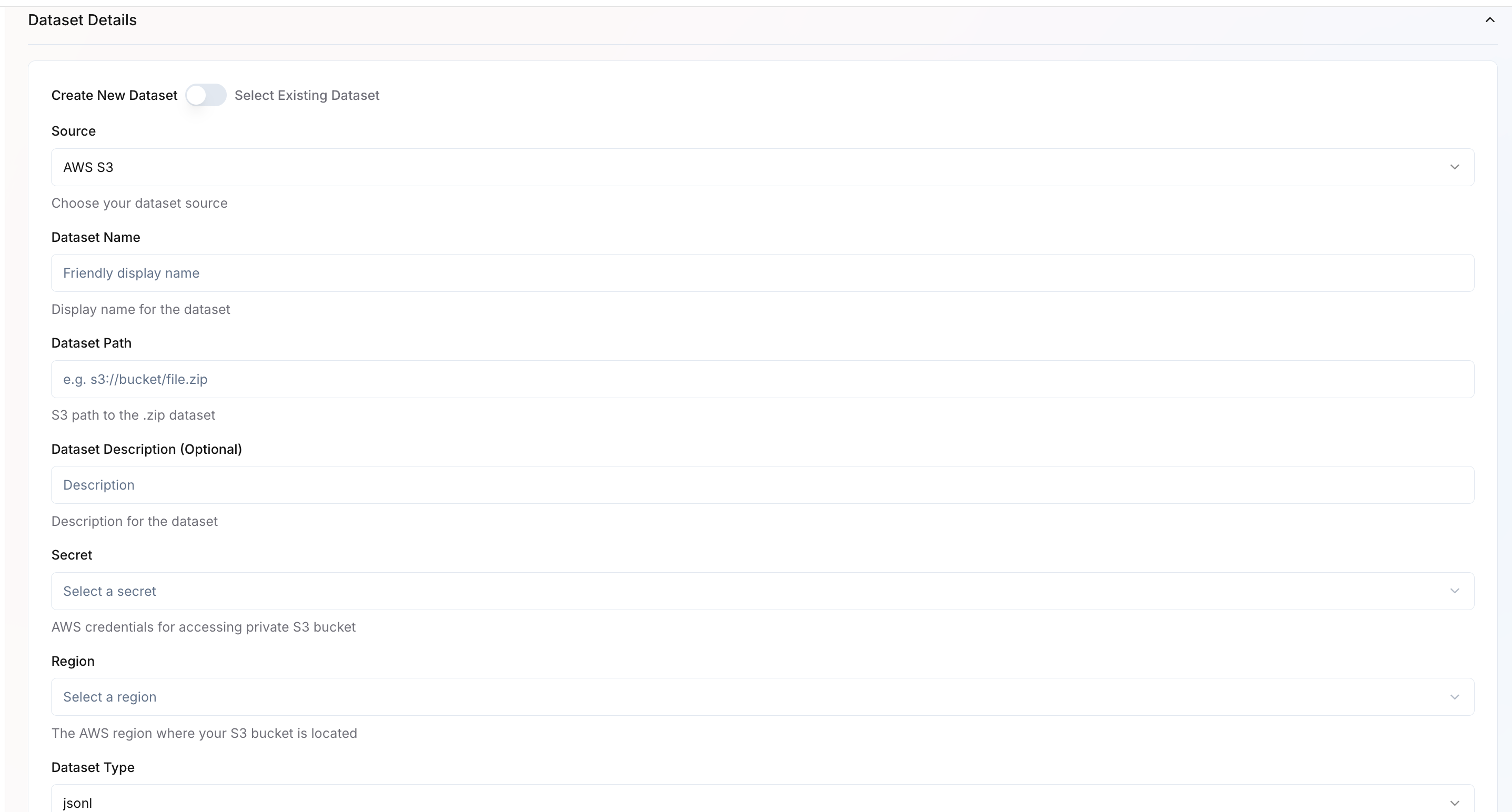 You can either create a new dataset or select an existing one.Create New Dataset
You can either create a new dataset or select an existing one.Create New Dataset