- Chat: Engage in interactive conversations with the model, simulating real-world dialogue.
- Configure Output: Adjust settings like output length, temperature and top-P to customize the responses generated by the model.
- Experiment with Prompts: Input different prompts and scenarios to see how the model responds, allowing for creative and practical applications.
- Evaluate Interactions: Analyze the generated text for coherence, creativity, and relevance to ensure it meets the required standards.
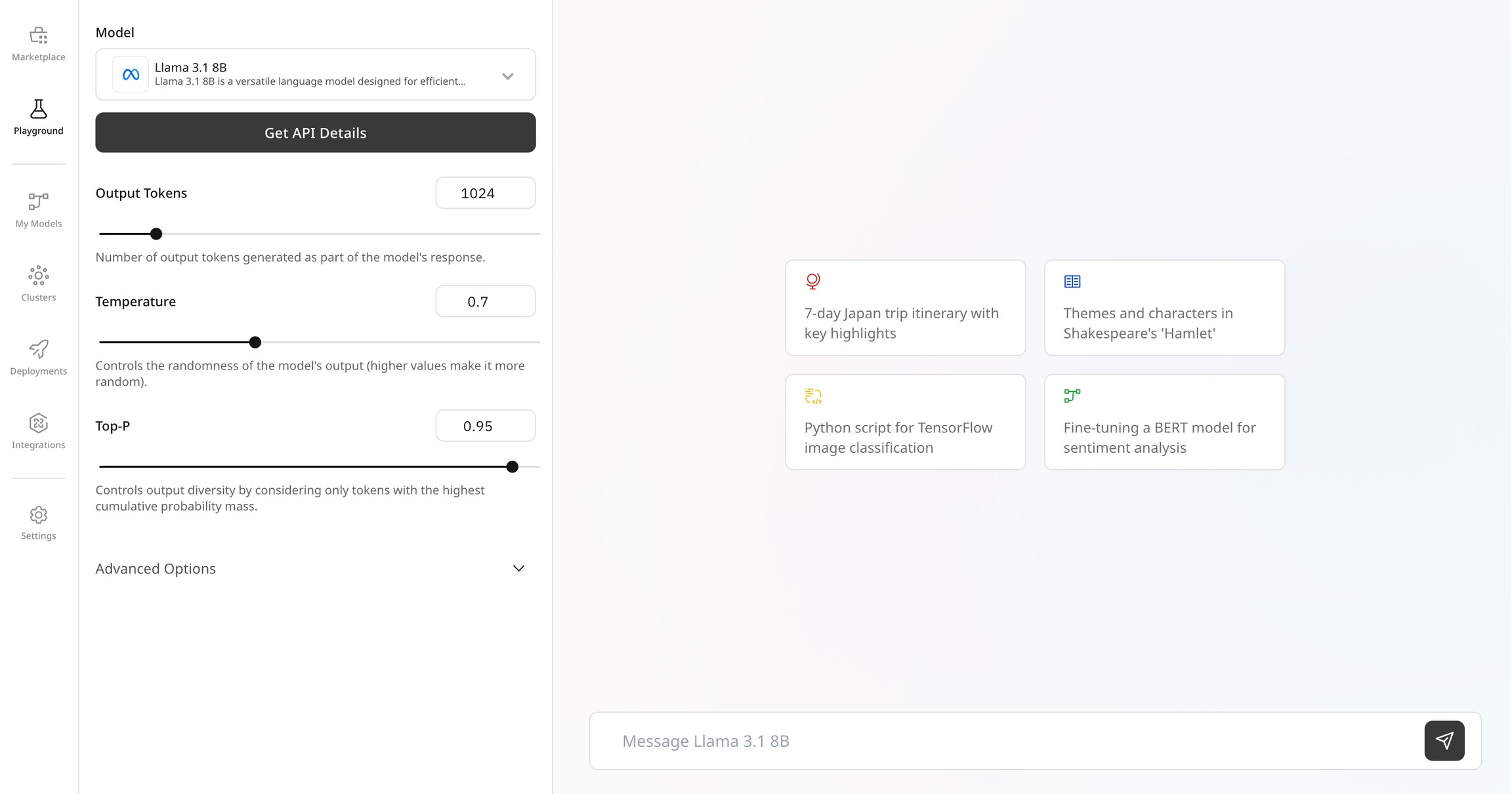
Settings explained
output tokens: The maximum length of the generated response, important for controlling the verbosity of the output.
temperature: Controls randomness in the output; higher values produce more creative results, while lower values yield more deterministic responses.
top-P: Uses nucleus sampling to choose tokens from the top P cumulative probability mass, balancing creativity and coherence.
stop sequence: Specific sequences that, when generated, will halt further output.
system prompt: The initial instruction or context setting the behaviour of the model.