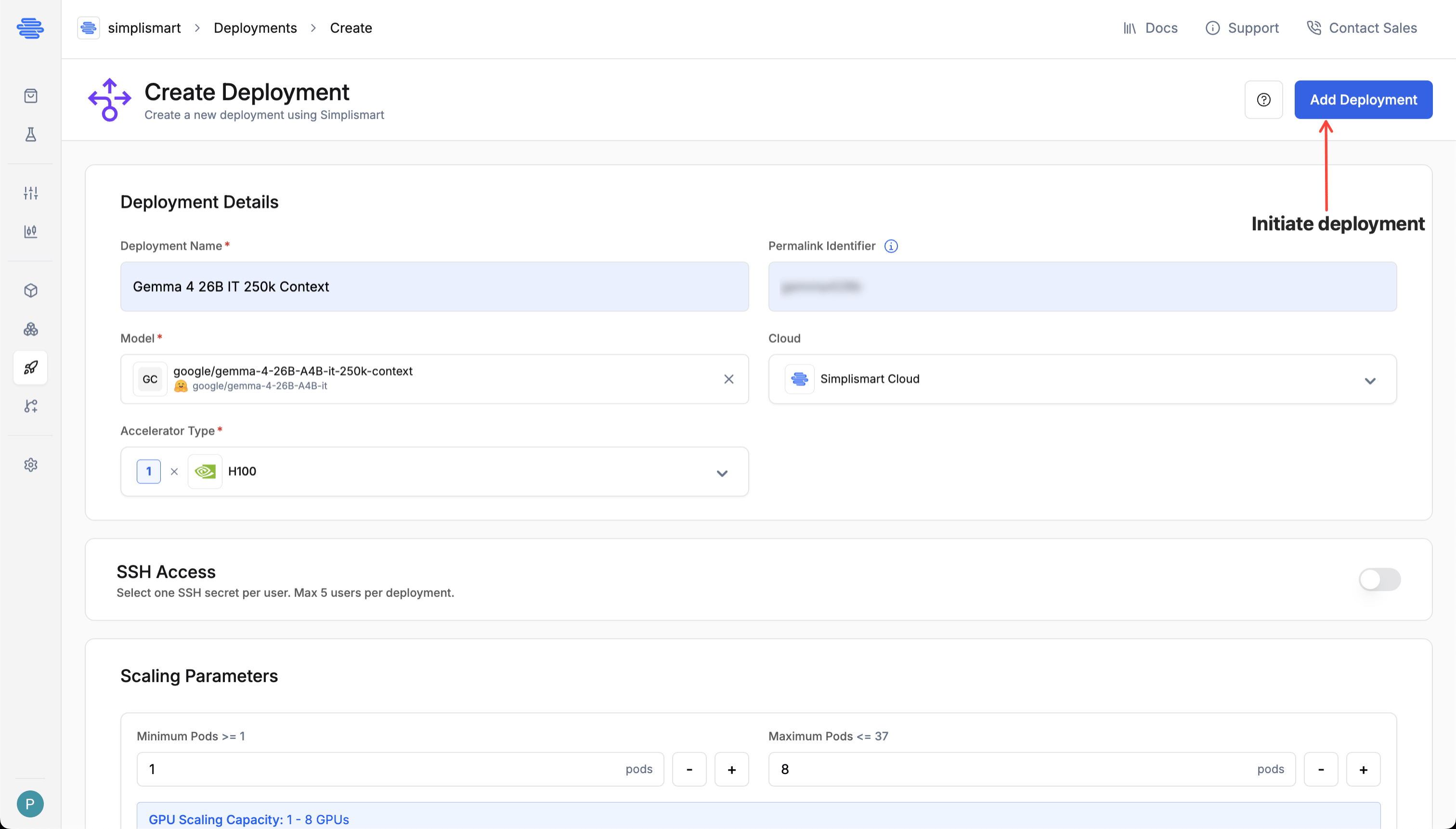
- Deployment Name: Provide a unique name for your deployment.
- Model: Choose the model you want to deploy from the dropdown.
- Cloud: Select Simplismart Cloud to deploy as a Dedicated Endpoint, or BYOC to deploy on your own cluster.
You can browse and select from available models in the My Models.
- Dedicated Deployment
- BYOC Deployment
Choose Accelerator
Choose the desired accelerator type based on your model size and SLA requirements.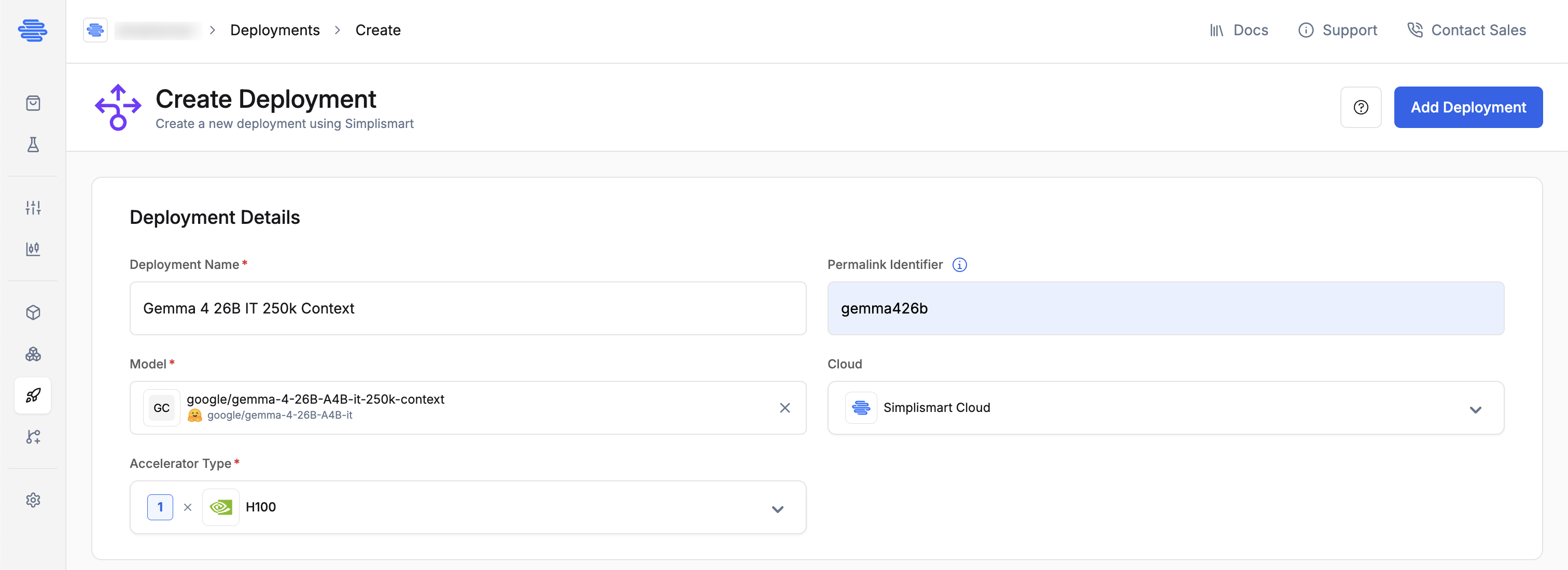
To deploy on a GPU type not listed or for CPU-only deployments, email support@simplismart.tech.
SSH Access
SSH access lets you connect directly to a running container in your deployment, which is useful for debugging, inspecting logs, or running ad-hoc commands without rebuilding and redeploying.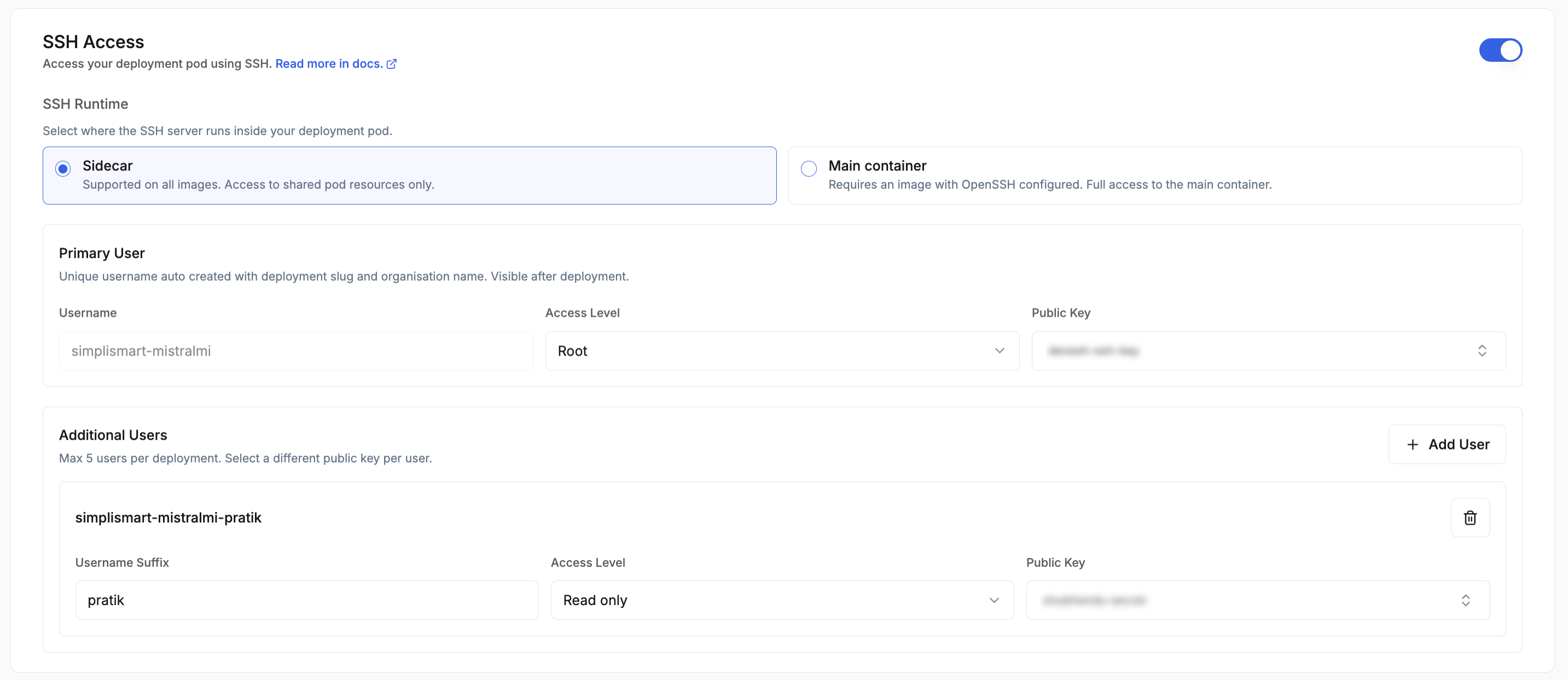
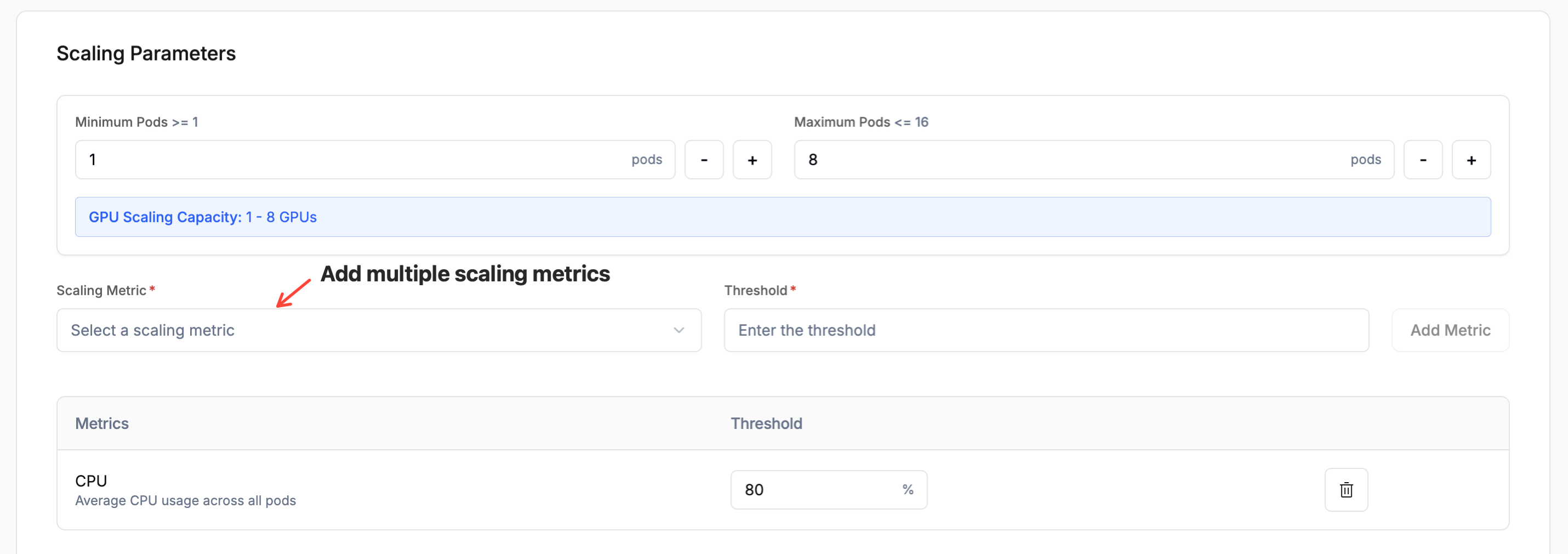
Scaling Parameters
Define how your deployment scales based on demand: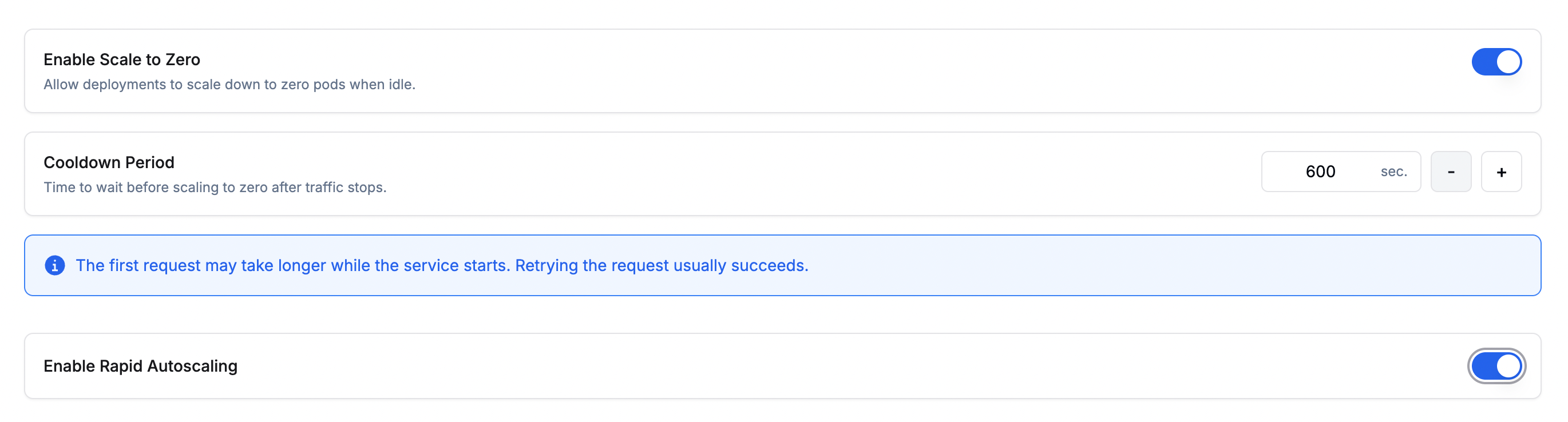
- Range: Minimum and maximum number of instances. The limits are governed by your account quota.
- Scaling Metric: The metric used to trigger scaling. Choose from:
- Memory Usage: Average memory usage across all pods.
- Latency: Response time per request.
- Throughput: Number of requests processed per second.
- Concurrency: Number of concurrent requests being processed.
Available scaling metrics may vary depending on the model type.
-
Threshold: The metric value that triggers a scaling event for both scale-out and scale-in (e.g. scale out at 80% memory, scale in when it drops back below the threshold).
- Enable Scale to Zero: Scales the deployment down to zero instances when there is no incoming traffic, reducing idle costs. When traffic resumes, the deployment scales back up automatically.
- Cooldown Period: The amount of time (in seconds) to wait after traffic stops before scaling down to zero. A longer cooldown avoids premature scale-downs during brief traffic lulls.
Rapid Autoscaling is available on Simplismart Cloud (Dedicated) deployments only. To enable it, contact support@simplismart.tech.
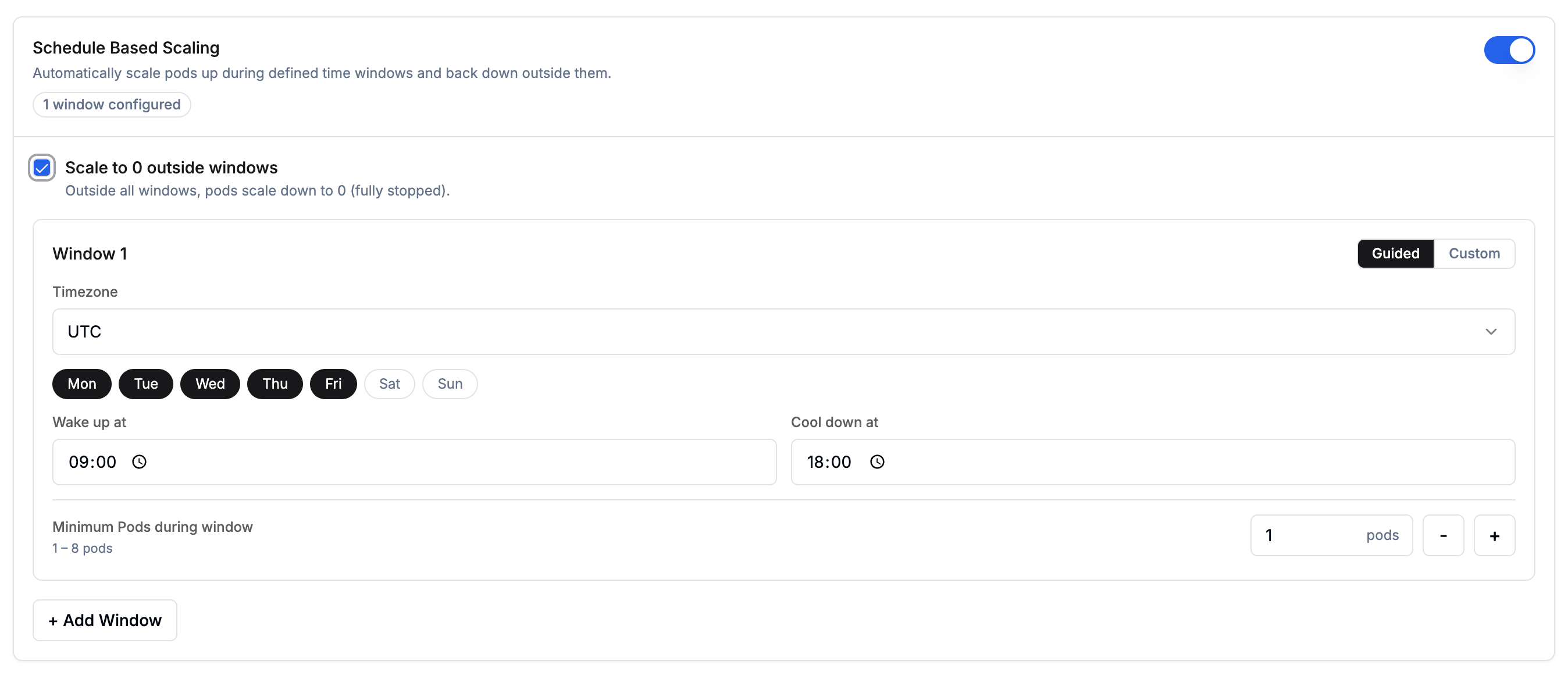
Schedule-Based Autoscaling
Enable Schedule Based Scaling when you know your traffic pattern in advance. For example, if most of your load arrives on weekdays during office hours, you can define time windows for those periods and let the deployment scale to zero, or fall back to a lower replica count, outside them.Scale to 0 outside windowsChoose what happens outside your configured windows:
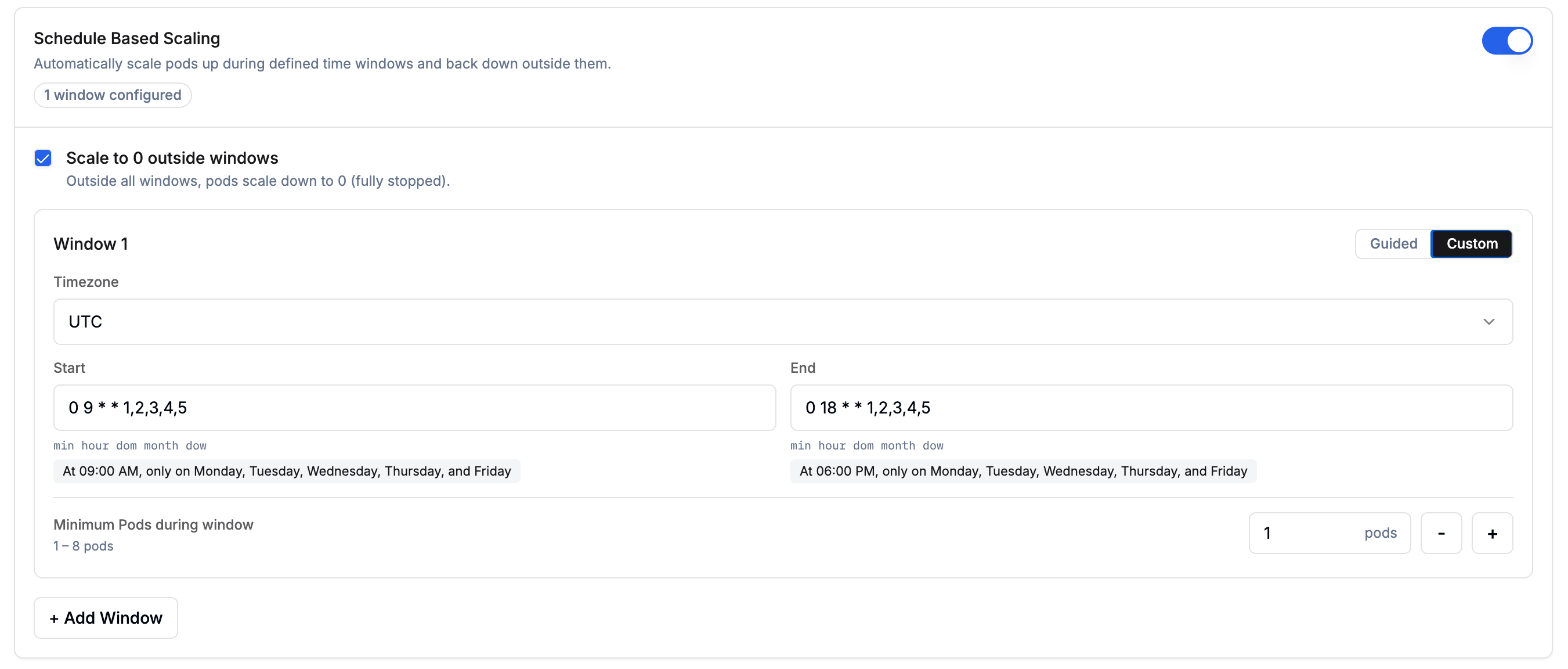
Pick Disabled if the endpoint must accept requests outside windows.Configuring windowsEach window defines a time range during which a guaranteed minimum number of pods is maintained. Click + Add Window to add more windows. When multiple rules are active (schedule windows, overlapping windows, standard scaling), whichever produces the higher pod count wins at any given time. The cool-down period is fixed at 5 minutes and cannot be modified.Each window can be configured using either the Guided visual picker or Custom cron expressions:
| Setting | Outside windows | Endpoint behaviour |
|---|---|---|
| Enabled | Deployment runs 0 pods. It wakes up at the start of the next window. | Returns 503 Service Unavailable until the next window starts. |
| Disabled | Deployment falls back to your standard min/max replicas. | Continues to serve traffic. |
- Guided
- Custom
Use the visual picker to configure your schedule:
- Timezone: the timezone for interpreting wake-up and cool-down times.
- Days: select one or more days of the week (Mon–Sun).
- Wake up at: the time at which pods scale up to the configured minimum.
- Cool down at: the time at which pods begin scaling down.
-
Minimum Pods during window: number of pods guaranteed during the window (1–8).
Autoscaling Policy
Fine-tune how aggressively your deployment scales up and down by configuring policies and stabilization windows for each direction. This controls the rate of pod changes once the scaling metrics cross their configured thresholds.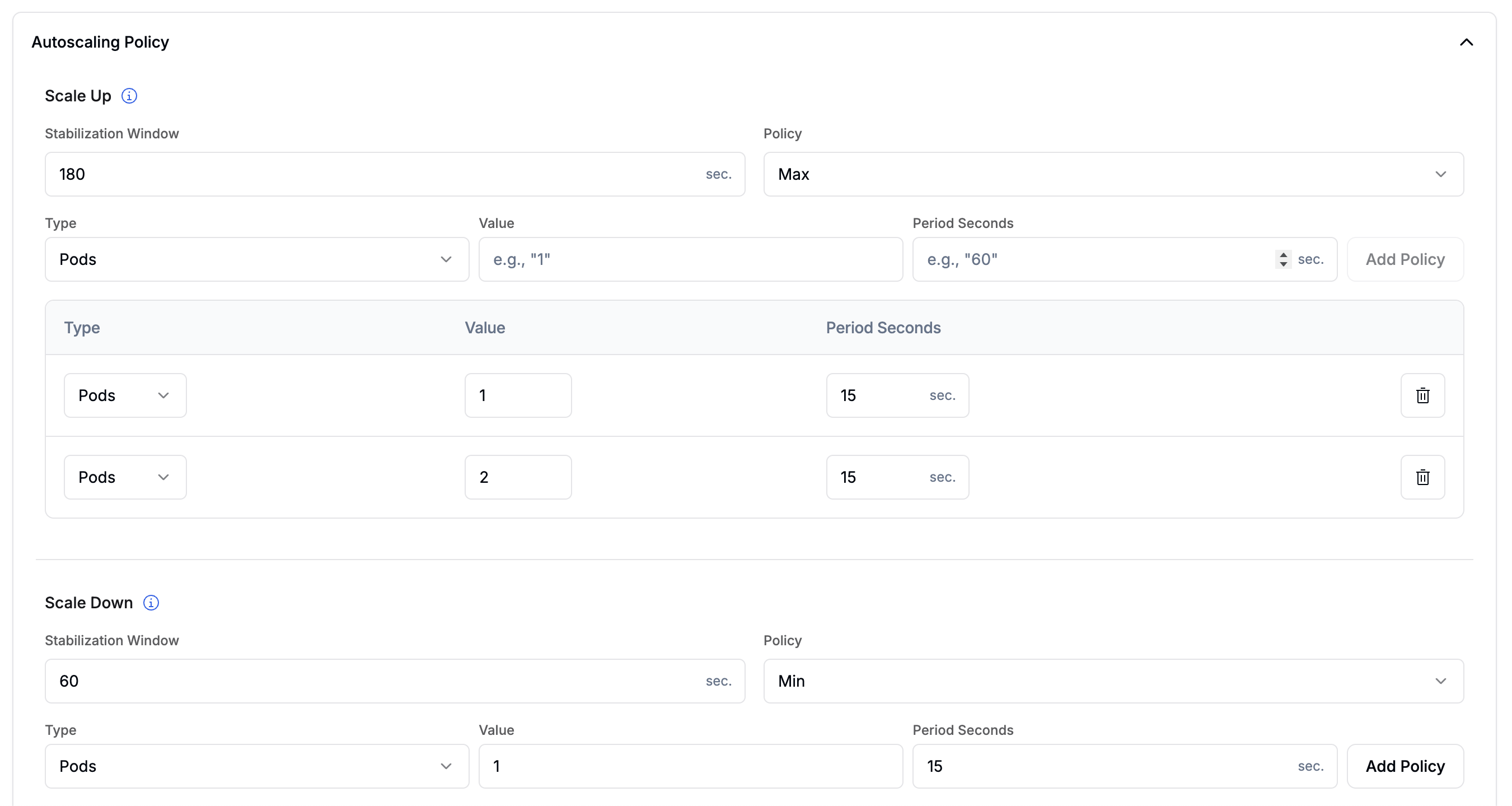
- Stabilization Window: the look-back period (in seconds) used to smooth out scaling decisions. Default:
60s. Range: 0–3600 s. - Select Policy: when multiple policies are configured, determines which one wins:
- Max (default): picks the policy that allows the most pods to be added.
- Min: picks the policy that allows the fewest pods to be added.
- Disabled: disables scale-up entirely.
- Policies: one or more rate-limiting rules. Click Add Policy to configure:
- Type:
Pods(fixed number per period) orPercent(percentage of current count, max 100). - Value: the number of pods or percentage to add per period.
- Period Seconds: the duration of each evaluation window (1–1800 s).
- Type:
When multiple policies are active, Select Policy = Max picks the policy that allows the largest increase.
- Stabilization Window: the look-back period (in seconds) before pods are removed. Default:
180s. Range: 0–3600 s. - Select Policy: when multiple policies are configured, determines which one wins:
- Min (default): picks the policy that removes the fewest pods.
- Max: picks the policy that removes the most pods.
- Disabled: disables scale-down entirely.
- Policies: same fields as Scale Up.
When multiple policies are active, Select Policy = Min picks the policy that removes the fewest pods. This ensures scale-down is gradual even if metrics drop sharply.
Autoscaling Policy is an advanced configuration. If left unconfigured, standard min/max replica scaling based on the configured scaling metrics applies without rate limiting.
Tags
Add key-value tags to organize and filter your deployments. Tags are useful for tracking environment, team, or cost-center metadata.
- Click + Add Tag to add a new key-value pair.
-
Tags can be used to filter deployments on the Deployments page.


Monitoring and Access
After the deployment is created, Simplismart continuously monitors the model server, waiting for the model weights to load and the server to begin responding. The deployment is marked Healthy once the model is fully loaded and ready to serve requests. Until then, the endpoint does not accept traffic. Health monitoring keeps running for the lifetime of the deployment. If a pod stops responding, Simplismart stops routing traffic to it and may replace it.Health states
The status shown on the deployment page reflects the current health of your deployment:| State | What it means |
|---|---|
| Progressing | Pods are coming up. The deployment is not yet ready to serve traffic. |
| Healthy | The deployment is live and accepting inference requests. |
| Progressing with timeout | The deployment has not become ready within the expected window. Check the Events tab to investigate. |
| Not present | The deployment has been stopped or deleted. |
| Unknown | Status could not be determined. Usually transient; if it persists, contact support. |
- Health Status: Shows Healthy on the deployment page.
- Deployment URL: Direct link to your running deployment. Use the API tab to find the endpoint URL and a pre-generated inference script. See Inference & Monitoring for a full walkthrough.
- Events Tab: Tracks lifecycle events such as health transitions, scale-out, scale-in, and instance restarts. Start here when debugging unexpected behaviour.
Managing Your Deployment
Once your deployment is live, you can manage it from the Deployments page:- Open the Deployments tab from the main menu.
- Select the deployment you want to modify.
- Click the kebab menu (
⋮) in the top-right of the deployment card and choose Pause, Edit, Clone, or Delete.
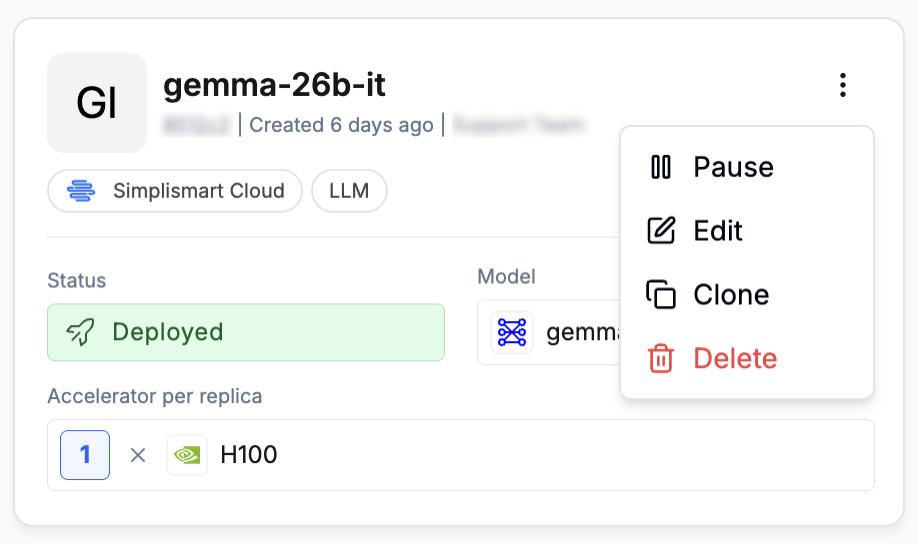
Edit Deployment
Adjust scaling, model, or tags without redeploying. Changes are applied as rolling updates.
Pause Deployment
Halts all running instances. The deployment configuration is preserved and can be resumed at any time.
Clone Deployment
Duplicates the current deployment’s configuration as a starting point for a new deployment.
Delete Deployment
Permanently removes the deployment and all its instances. This action cannot be undone.