Merge with Base Model
Click on Compile to merge the LoRA adapter back into the base model, creating a fine-tuned model. This step will take you to the Add Model page. Follow the next steps to create an optimised version of the model ready to be deployed via the Simplismart Model Suite.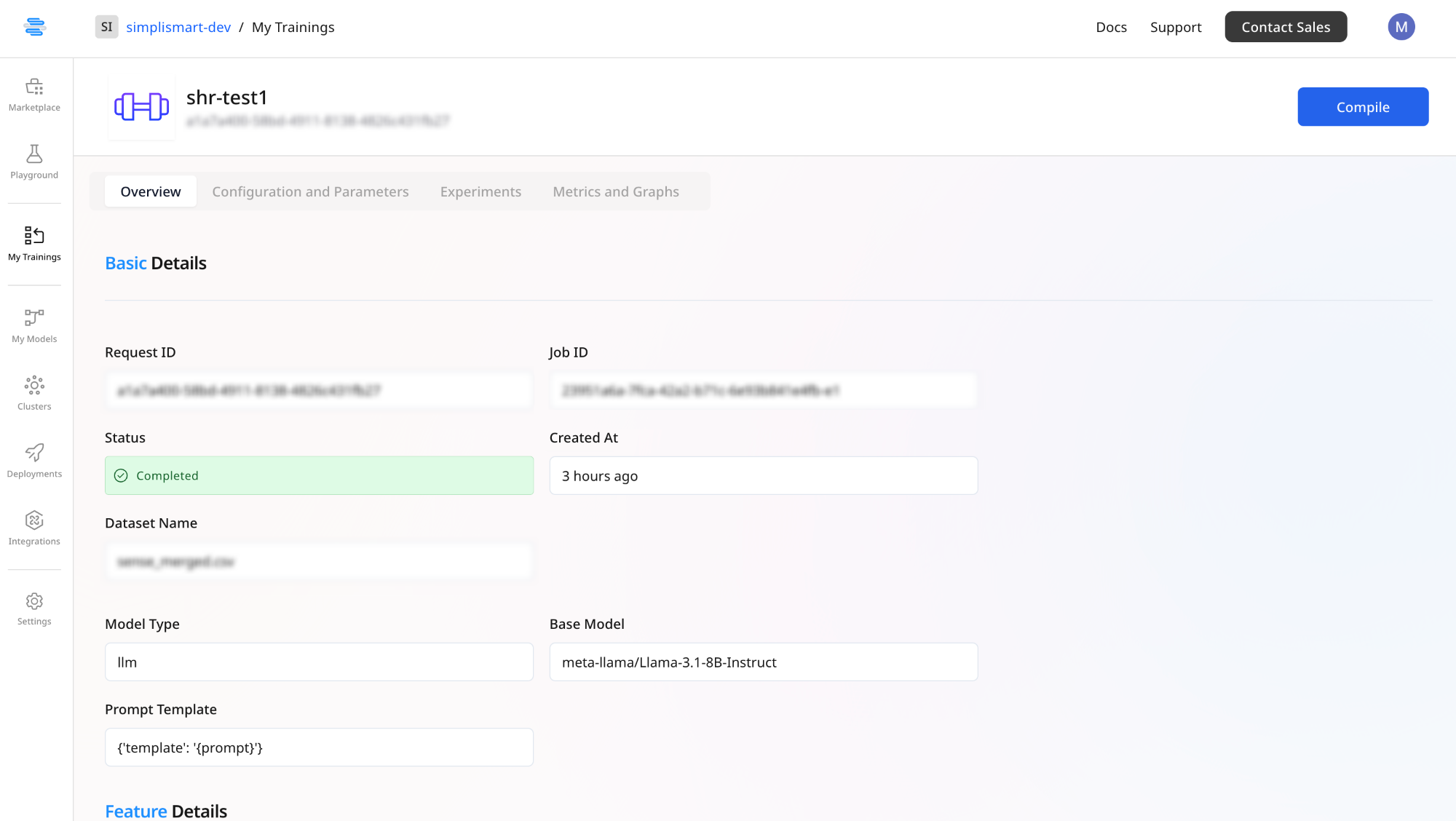
Optimize the Fine-Tuned Model
While compiling the LoRA with the base model, you will have the option to optimize the model for deployment.Enter Model Details
Provide the name for your fine-tuned model.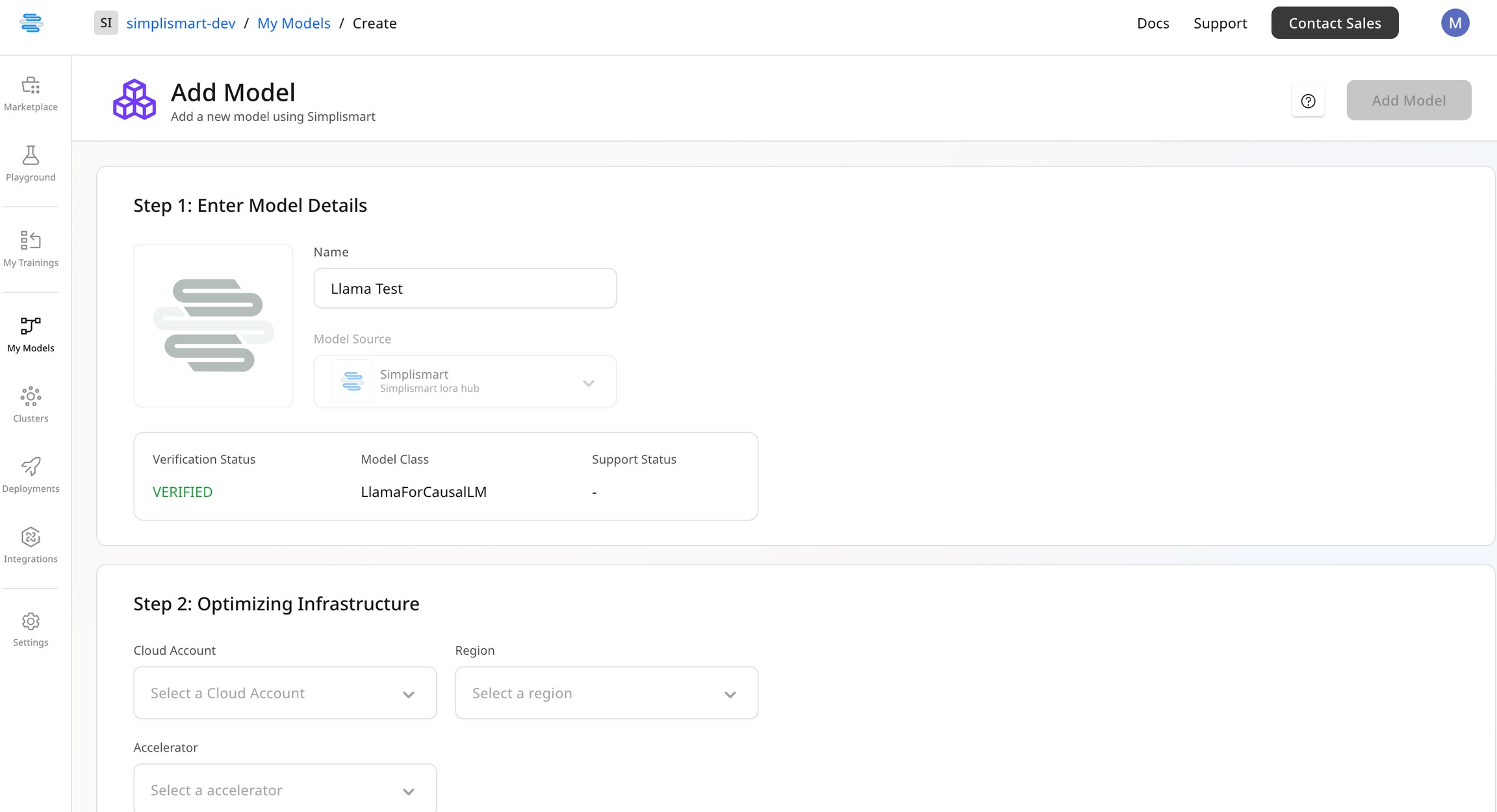
Select Optimizing Infrastructure
Choose the right optimization infrastructure for the model based on the size of the base model, specifically the GPU RAM required to run the model for a given quantization.For example, a Llama 3.1 8B model can run on a T4 GPU with a 4-bit quantization but may run into CUDA OOM errors with an FP16 quantization.
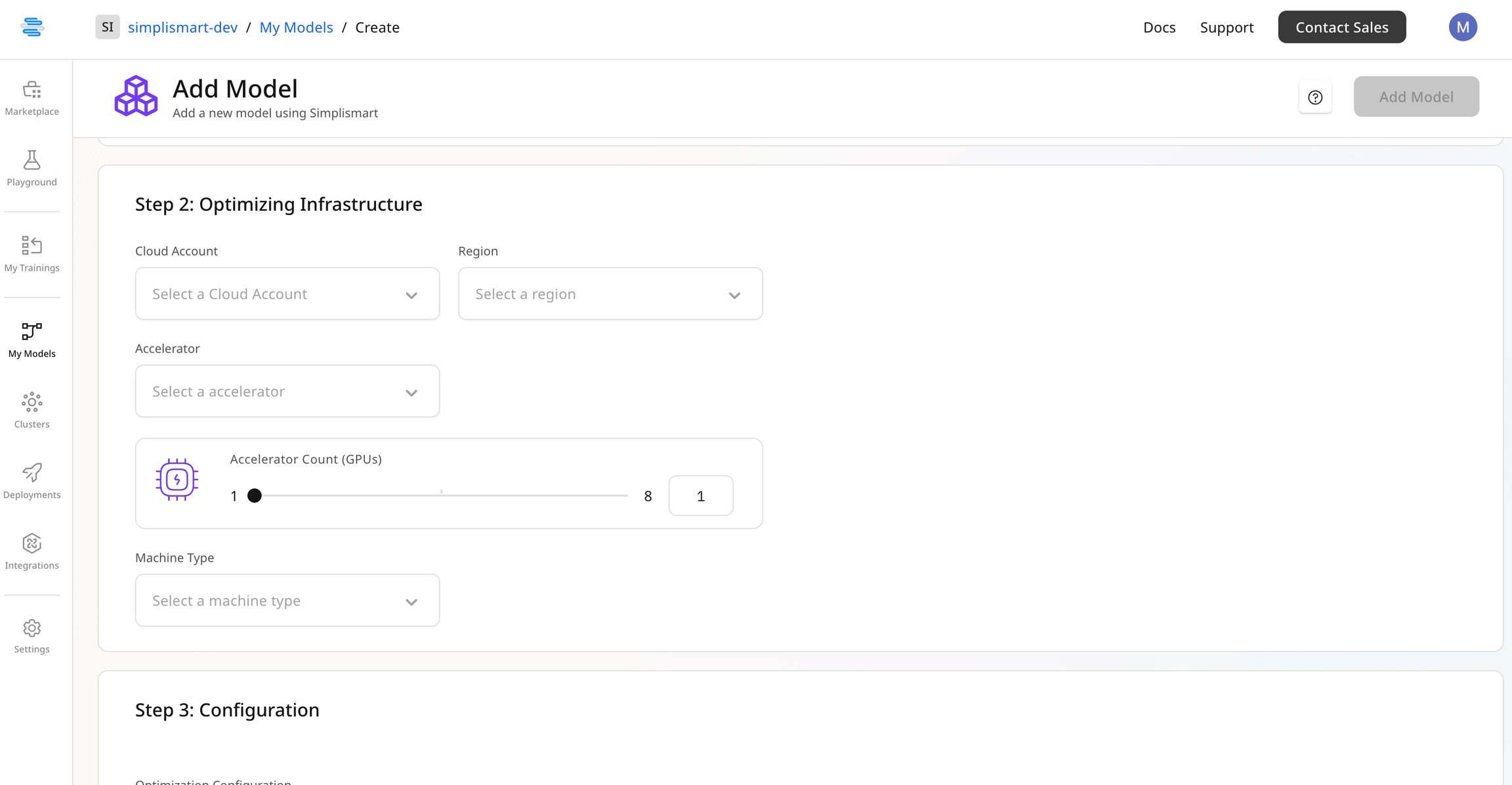
Update Optimization Configuration
Modify the optimization settings as needed, and select the desired quantization for your optimised model. If unsure about the rest of the optimization configuration, leave it at the default values.Please refrain from changing the model configuration in this step.