1. Enter model details
Navigate to Add Model to register a new model in Simplismart.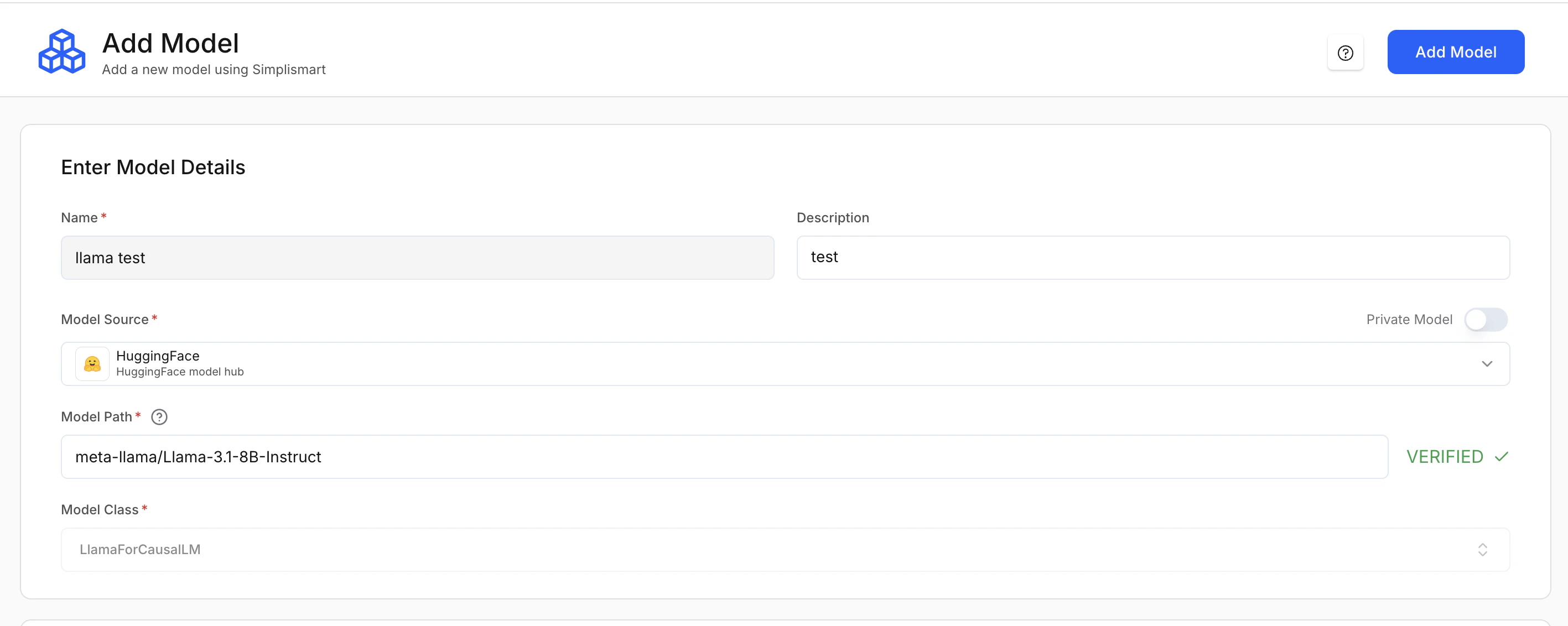
- Name (Required): A unique identifier for the model within the platform.
- Description (Optional): Short note about the model’s purpose.
Model source (required)
Specifies where the model artifacts are loaded from.| Option | Description |
|---|---|
| Hugging Face (HF) | Load directly from the Hugging Face Hub |
| AWS S3 | Load from an S3 bucket |
| GCP GCS | Load from a Google Cloud Storage bucket |
| Public URL | Load from a publicly accessible URL |
If you use a private model from Hugging Face, add your Hugging Face access token as a secret in Integrations first, then select that secret when configuring the model.
Getting your model path from Hugging Face
Getting your model path from Hugging Face
- Go to huggingface.co.
- Use the search bar to find the model (e.g. “whisper-large”).
- Open the model from the results (e.g.
openai/whisper-large-v3-turbo). - Copy the model path at the top of the page (format:
creator/model-slug).
Model path (required)
The exact path to the model. The platform verifies the path automatically.- Hugging Face:
meta-llama/Llama-3.1-8B-Instruct - AWS S3:
s3://my-bucket/model/ - GCP GCS:
gs://my-bucket/model/ - Public URL:
https://<host>/model
Cloud credentials: For AWS S3 or GCP GCS, provide the relevant cloud credentials in Secrets tab so the platform can access private storage.
Model class (required)
Defines the pipeline or architecture class used to load the model. This is usually auto-selected from the model source and path. Here are some examples of model classes:| Class | Use case |
|---|---|
LlamaForCausalLM | LLMs |
WhisperForConditionalGeneration | Speech (ASR) models |
FluxPipeline | Diffusion models |
CustomPipeline | Custom or non-standard pipelines |
2. Optimising infrastructure
This section determines where the model will be deployed. Configuration depends on whether you choose Simplismart Cloud or Bring Your Own Cloud (BYOC).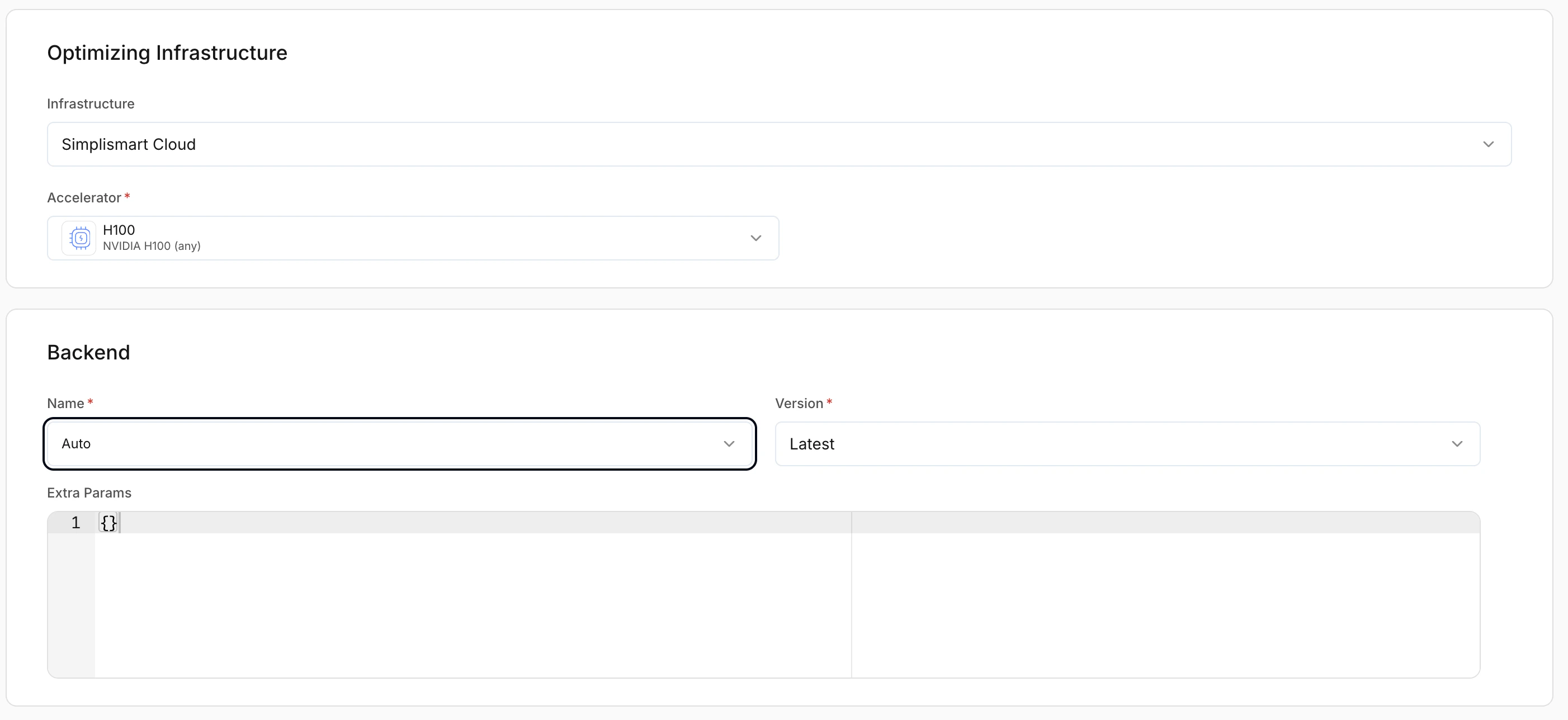
3. Model-specific configuration
After model details and optimising infrastructure, the remaining settings depend on the type of model you are adding:- LLMs: Chat, completion, embedding
- Diffusion models: Image generation
- Speech (ASR / Whisper): Transcription
- Custom pipelines: User-defined or non-standard architectures. For more information check out this doc on adding a custom model.
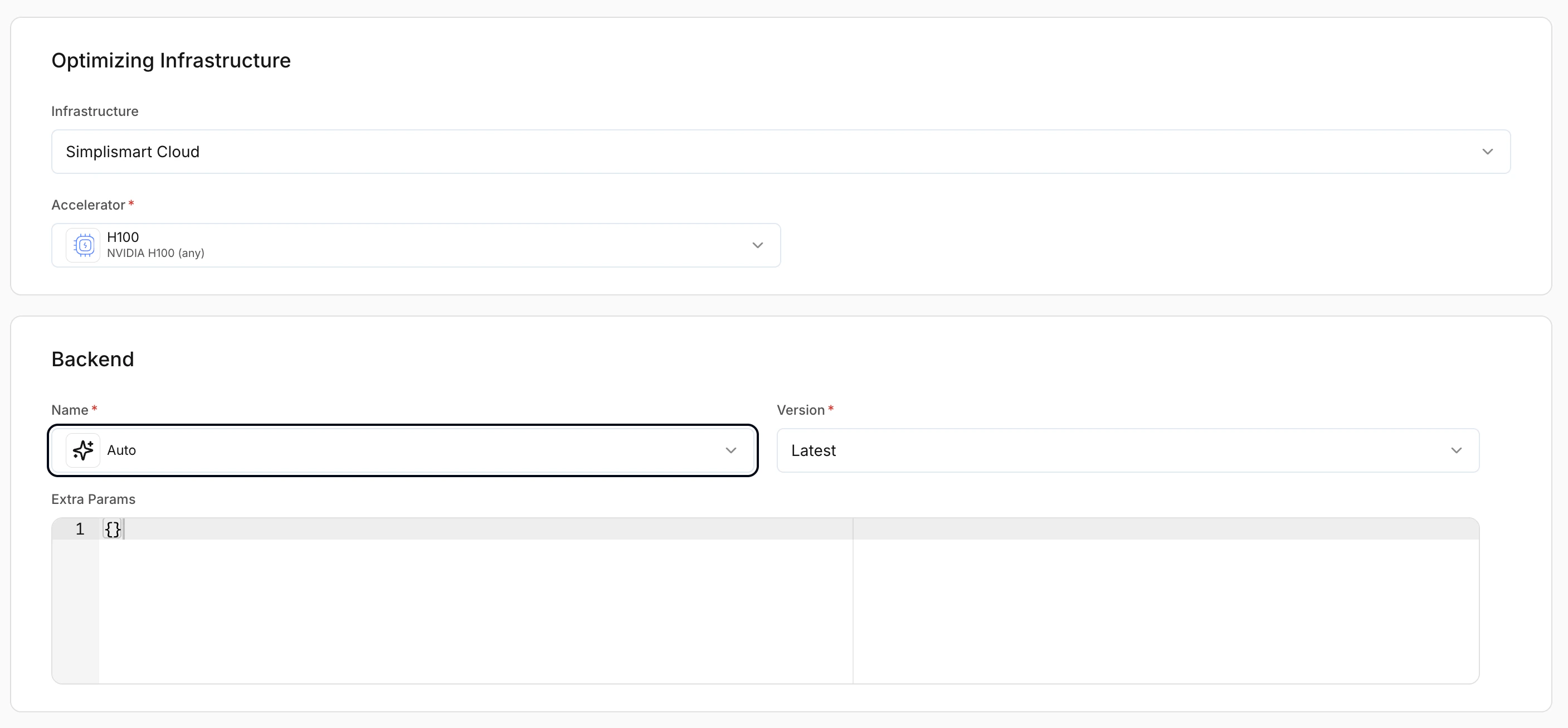
Adding LLMs
LLM models include chat, completion, and embedding workloads.By default, the platform selects the most suitable compilation settings for LLMs based on the model architecture.
Backend selection
Controls the inference backend used to serve the model. LLMs support multiple optimised backends.- Auto: Simplismart selects the optimal backend automatically.
- Latest: Recommended unless you need a specific version.
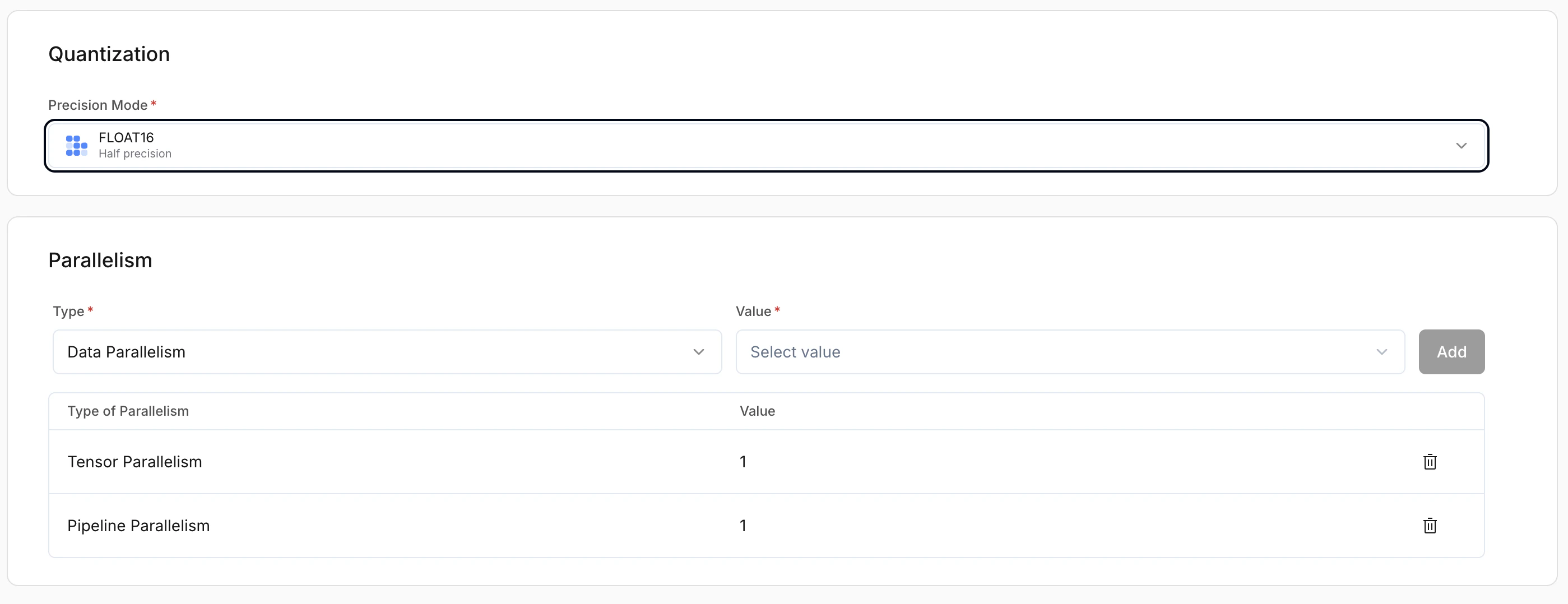
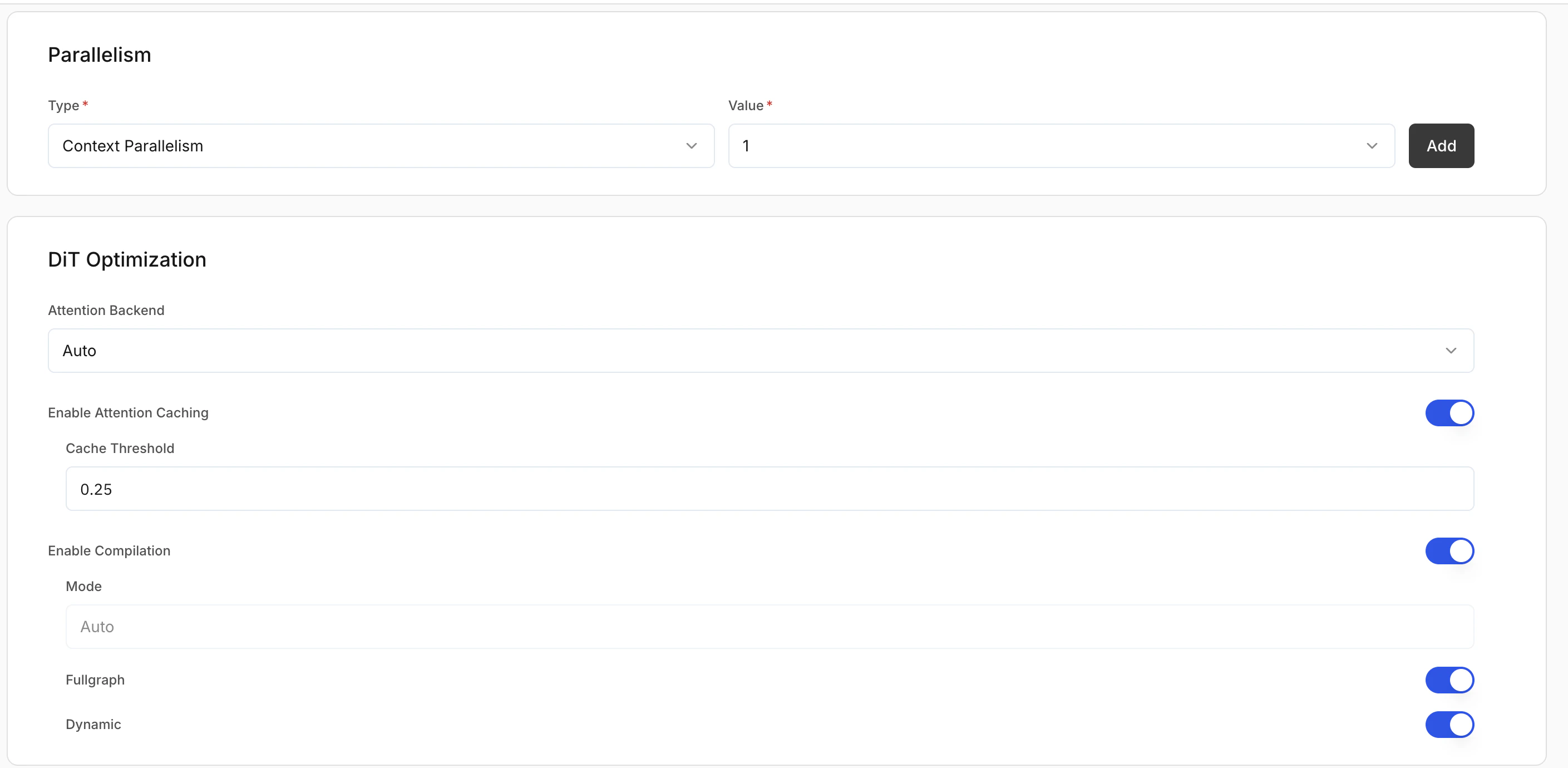
Parallelism
| Strategy | Description | Use case |
|---|---|---|
| Data parallelism | Full model replicated on each GPU; each GPU handles separate requests | Higher throughput; concurrent traffic |
| Pipeline parallelism | Model layers split across GPUs; each GPU holds part of the model | When the model is too large for a single GPU |
| Expert parallelism | For Mixture-of-Experts (MoE); experts distributed across GPUs | MoE scalability and efficiency |
Pipeline task
Defines what the model is used for. This affects request/response formatting and runtime behaviour.- Chat: Conversational models
- Completion: Text generation
- Embedding: Vector generation models
Speculative decoding (optional)
Improves latency by generating tokens using a draft strategy. Recommended: On for chat and completion workloads.Extra params
Advanced backend-specific configuration in JSON format. Leave empty unless you need custom tuning.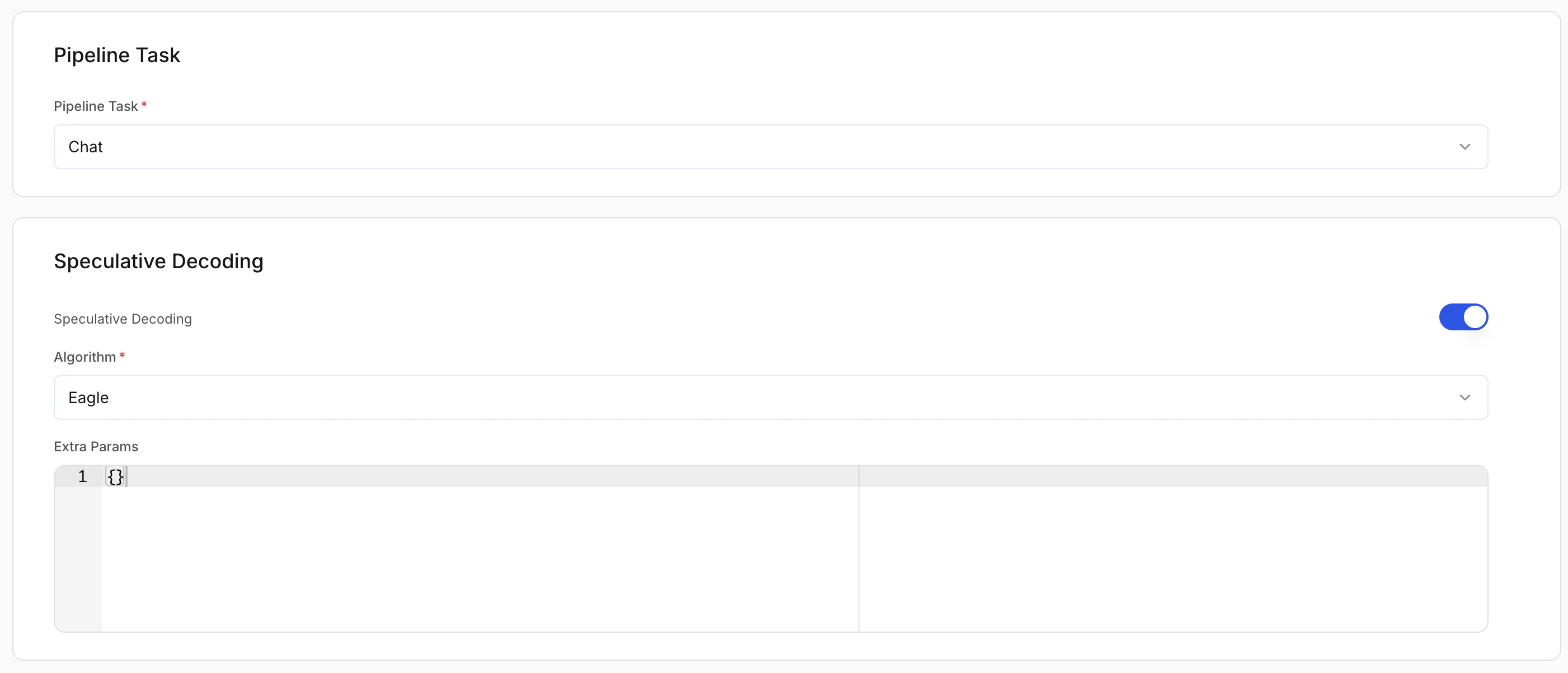
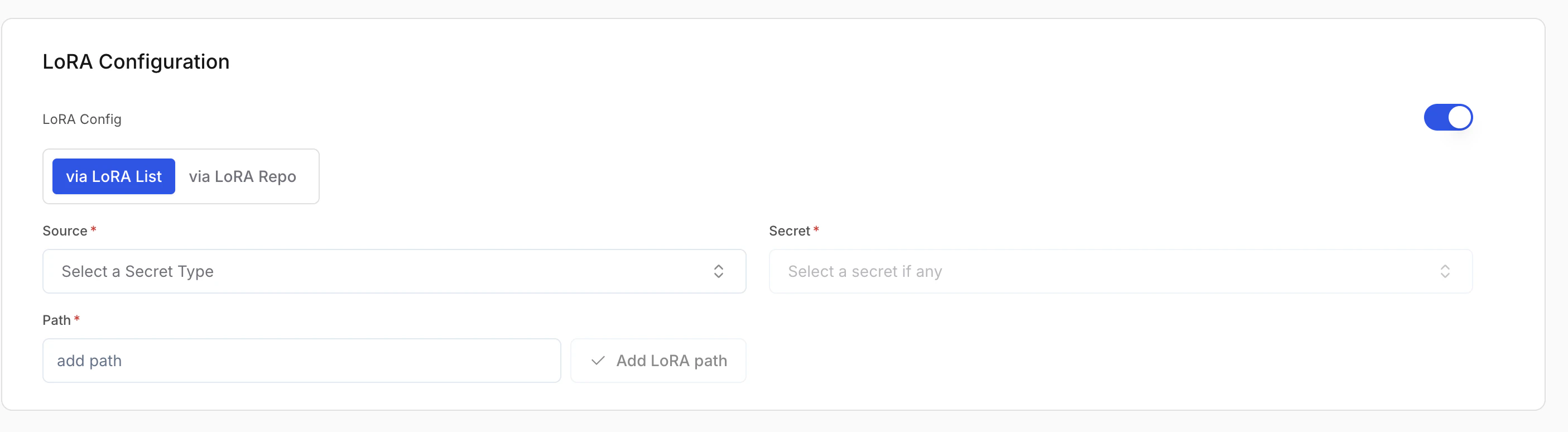
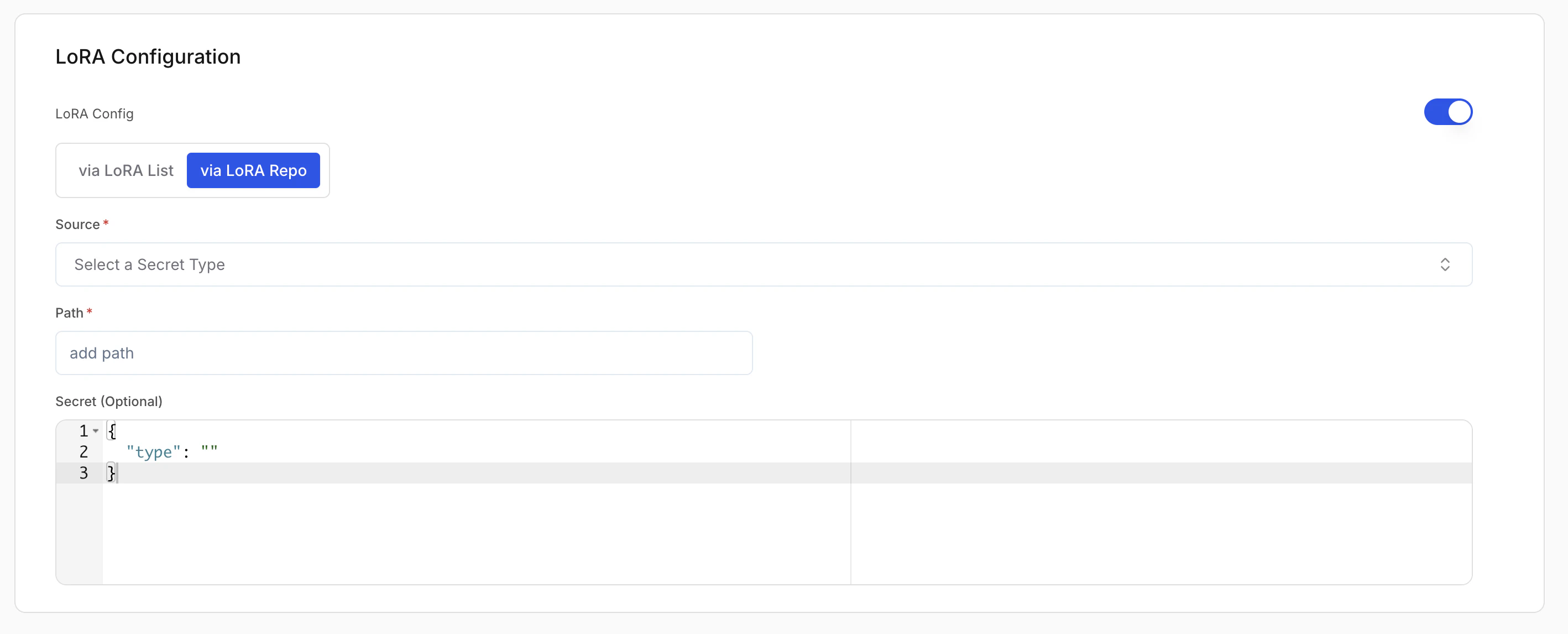
LoRA configuration (optional)
LoRA (Low-Rank Adaptation) lets you load fine-tuned adapters on top of a base model.- Enable LoRA: Turn this on to attach LoRA adapters to the base model.
- Via LoRA list: Add adapters from different sources (e.g. one from Hugging Face, another from S3). Use Add LoRA path for each adapter.
- Via LoRA repo: Add all adapters from a single source in one go. Use Add LoRA Repo and give one repo location; the platform fetches every LoRA in that repo.
| Field | Description |
|---|---|
| Source (Required) | Where the weights are stored (e.g. AWS S3, Hugging Face, GCP GCS). |
| Secret (Required) | Credentials for that source. Create or pick a secret in Secrets. |
| Path (Required) | Adapter location in the source (e.g. s3://my-bucket/my-lora). |
For Via LoRA repo, the secret field must be in the JSON format expected by the platform. See Secrets for the required format.
Adding diffusion models
Parallelism
| Type | Description | Use case |
|---|---|---|
| Context parallelism | Splits input context or latent representation across GPUs | High-resolution image generation; memory-intensive models |
| Fully shared data parallelism | Replicates the model across GPUs; each GPU handles separate requests | High-throughput production; concurrent image generation |
DiT optimisation (diffusion only)
Attention backend: Selects the attention implementation during inference.- Flash: Optimised attention for better performance.
- Torch: Standard PyTorch attention.
- Auto: Platform selects the best option.
Additional optimisation settings
- Enable attention caching: Caches attention states to reduce repeated computation and improve speed.
- Cache threshold: When caching is applied (default:
0.25). Higher values can improve speed but may reduce output quality. - Enable compilation: Compiles the model graph for faster inference.
- Fullgraph: Compiles the entire model for maximum performance.
- Dynamic: Supports variable input shapes.
Adding ASR (speech) models
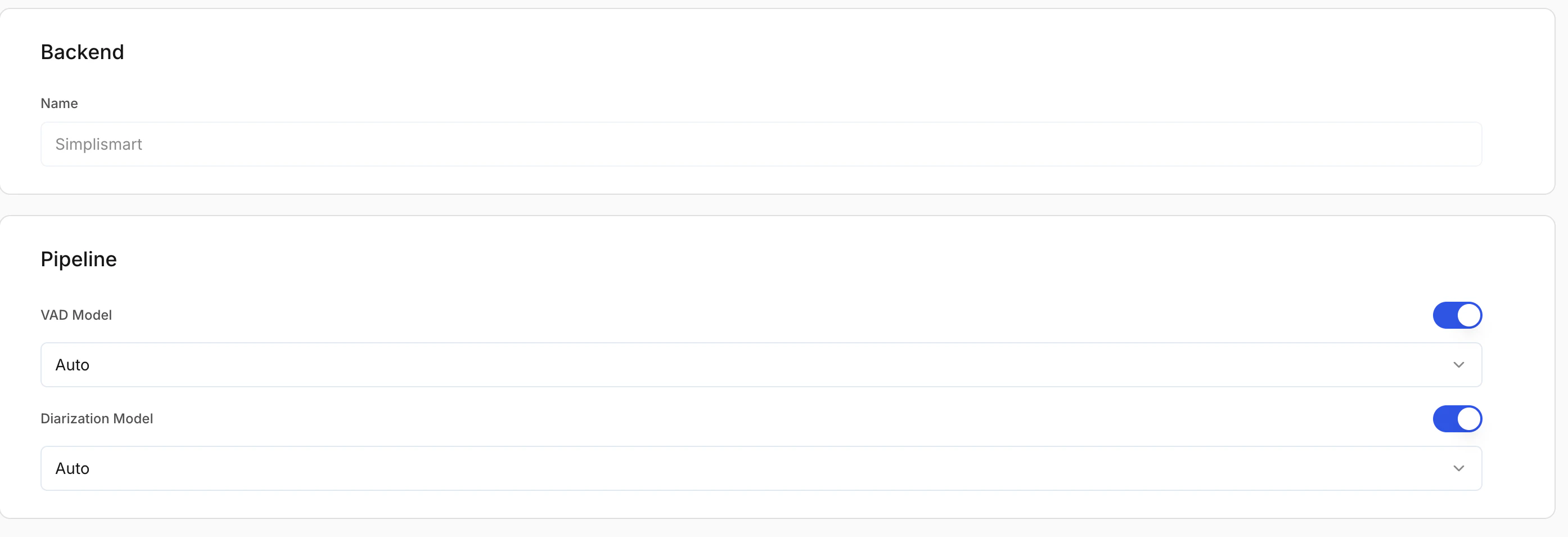
Optional pipeline add-ons
Voice activity detection (VAD) model
Detects speech segments and removes silence before transcription. VAD options:- Auto: Platform selects the best VAD.
- Silero: Lightweight, fast VAD.
- Frame: Frame-based detection.
Diarization model (optional)
Separates and labels different speakers in the audio.Enable diarization if you need speaker-wise transcripts.