Comprehensive guide of the Simplismart training suite for LLMs and VLMs
This updated guide provides an overview of our enhanced UI for training large language models and vision language models, supporting both Supervised Fine-Tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). For each training type, you can choose between full-model fine-tuning or parameter-efficient approaches like LoRA.While full-model fine-tuning is fully supported across both SFT and RLHF, we recommend using LoRA for most use cases due to its faster convergence, lower GPU memory usage, and simplified checkpointing.
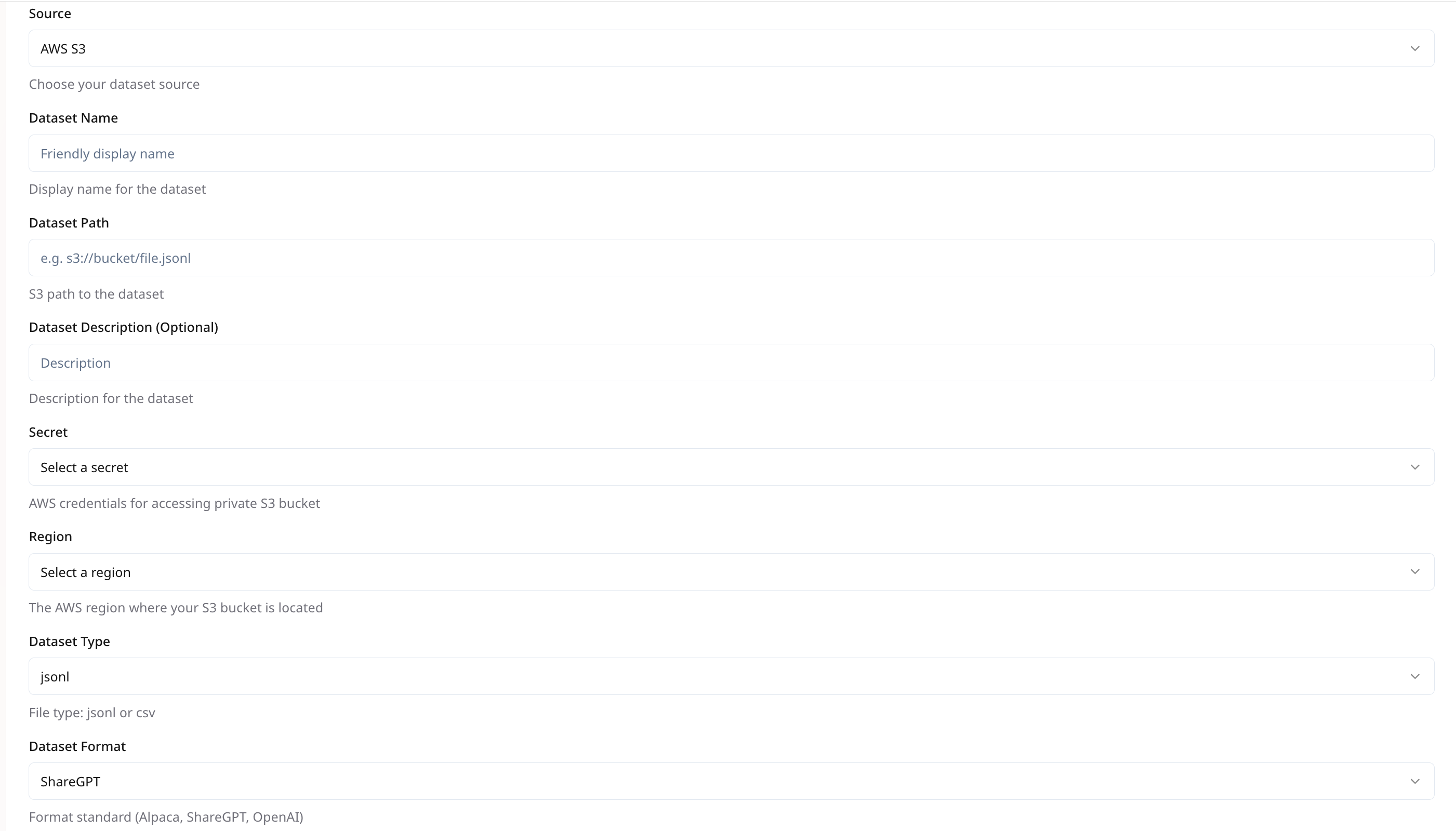
For VLM models, use a ZIP file containing both the image files and a train.jsonl file (the master training file).
The directory should be archived in a .zip file and stored in an object storage.
Example zip command:cd path/to/dataset_dir && zip -r dataset_dir.zip ./*
Each line in a .jsonl file should represent a complete training example. The supported format styles are:
{ "messages": [ {"role": "system", "content": "You are a useful and harmless assistant"}, {"role": "user", "content": "Tell me tomorrow's weather"}, {"role": "assistant", "content": "Tomorrow's weather will be sunny"} ], "rejected_response": "I don't know"}
Full – Use this option for full-model fine-tuning, where all model parameters are updated.
LoRA – Use this for parameter-efficient fine-tuning using Low-Rank Adapters (LoRA), which updates a small subset of weights for faster training and lower resource usage.
Note: LoRA is generally recommended for efficiency and ease of deployment.
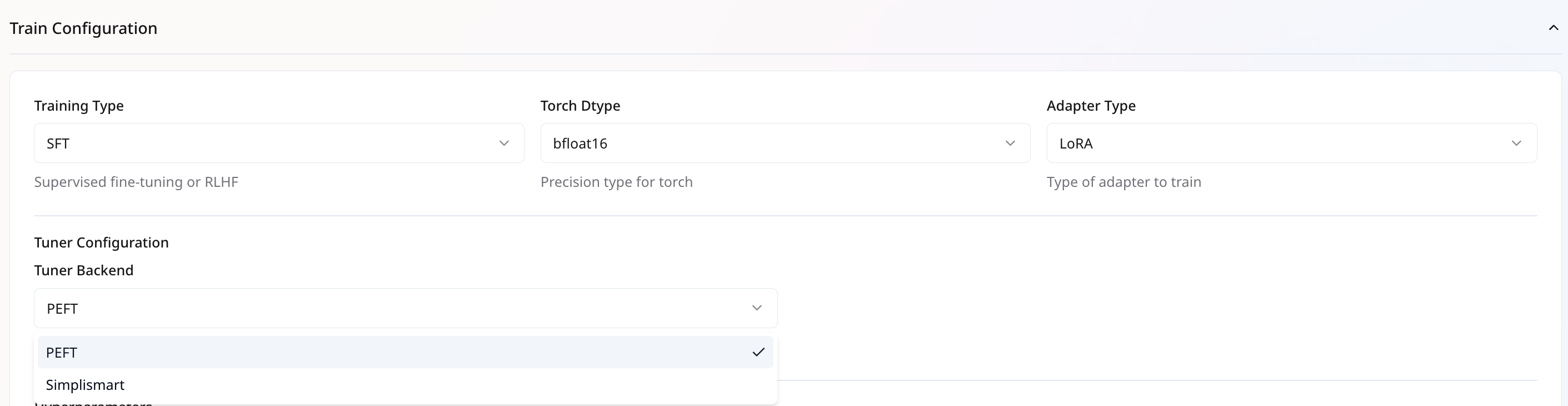
Tuner Backend(Applicable only for SFT Training type)
The Tuner Backend defines the framework used to run fine-tuning and enables faster performance through efficient training strategies.
PEFT (Parameter-Efficient Fine-Tuning) Backend
Standard backend widely used for LoRA-based fine-tuning.
Supports distributed training with either DDP (Distributed Data Parallel) or DeepSpeed.
Simplismart Backend
Optimized backend designed for more efficient GPU compute and memory utilization.
Currently supports only DDP for distributed training, ensures consistent and predictable scaling across multiple GPUs.
DDP replicates the model across GPUs and synchronizes gradients at each step, providing stable multi-GPU training.DeepSpeed adds advanced features like optimizer state partitioning, gradient sharding, and memory offloading, enabling the training of larger models on limited hardware.
RLHF Configuration (Applicable only for RLHF Training type)When selecting Training Type = RLHF, additional configuration fields appear under RLHF Config. These vary depending on the chosen RLHF Type. The platform supports the following RLHF variants:
DPO (Direct Preference Optimization)
Beta
Controls the trade-off between preference loss and KL regularization. Default:0.3 Optional: Yes, but recommended.
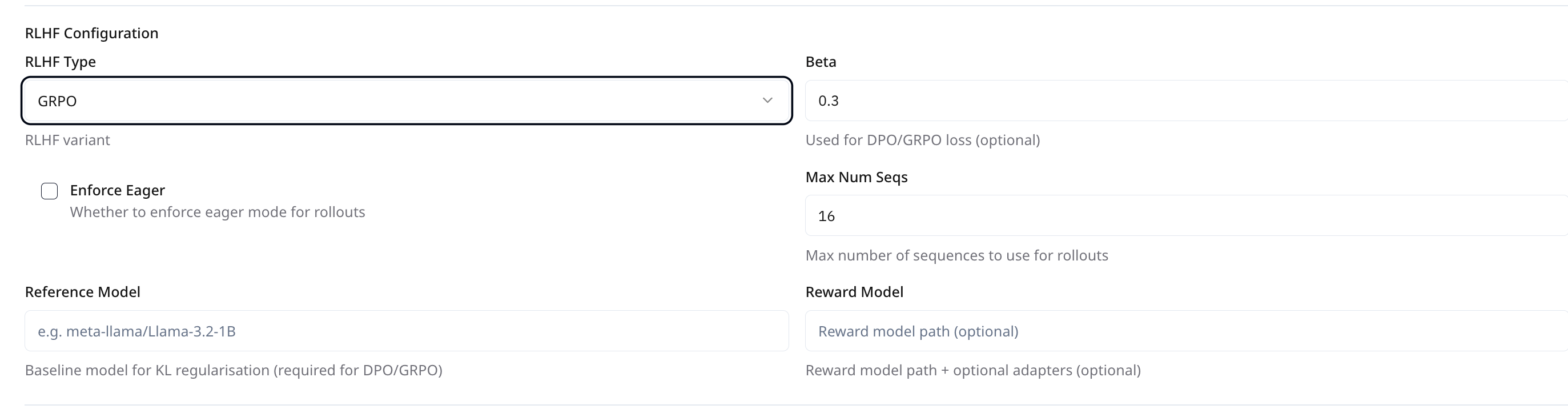
GRPO (Generative Rollouts with Preference Optimization)
Beta
Similar to DPO, this governs the preference vs. KL loss balance. Default:0.0001
Max Num Seqs
Number of sequences to use during rollout. Default:1 Recommended Value:1
Enforce Eager
If enabled, forces rollouts to run in eager mode rather than compiled mode. Useful for debugging or compatibility issues. Default: Unchecked Recommended: We suggest enabling Enforce Eager during GRPO training.
Common Parameters:
Field
Description
Required
Default
RLHF Type
Select the RLHF variant to use
✅
-
Reference Model
Path to the baseline model used for KL regularization
Optional
-
Reward Model
Path to the reward mode
Optional
-
Optimization Hyperparameters
Parameter
Description
Default Values
Recommended Values
Permissible Range
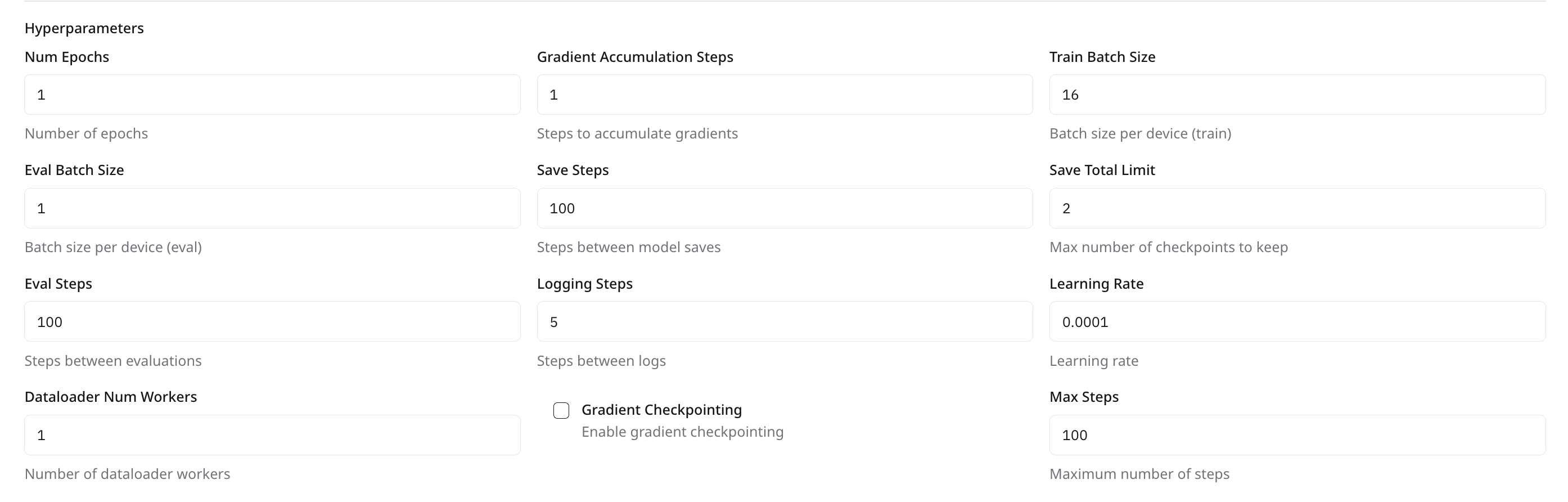
Num Epochs
Number of full passes through the dataset
1
2-5
< 50
Train Batch Size
Samples per device for training
8
8
< 16
Eval Batch Size
Samples per device for evaluation
1
8
<16
Learning Rate
Initial learning rate for optimizer
0.0001
1×10⁻⁵ to 2×10⁻⁵
< 5×10⁻⁵
Dataloader Num Workers
Parallel data-loading threads per device
1
4
<10
Hide Train Batch Size & Eval Batch Size
These values are highly dependent on your GPU count. The provided defaults are optimized for setups with 8 GPUs and are suitable for models in the 3B–5B parameter range. Adjust accordingly based on your GPU configuration.
For larger models, consider reducing the batch size to avoid out-of-memory issues.
Example: For an 8B model, we recommend using a train batch size and eval batch size of 4 each.
(Note: this configuration works with DeepSpeed Zero3_Offload)
Checkpointing & Monitoring
Parameter
Description
Default
Recommended Values
Permissible Range
Save Steps
Interval (in steps) between saving model checkpoints.
100
100
<= 100
Save Total Limit
Max number of checkpoints to keep locally.
2
2-5
<10
Eval Steps
Interval (in steps) between running evaluation loop.
100
100
100 - 200
Logging Steps
Interval (in steps) between logging metrics to the dashboard.
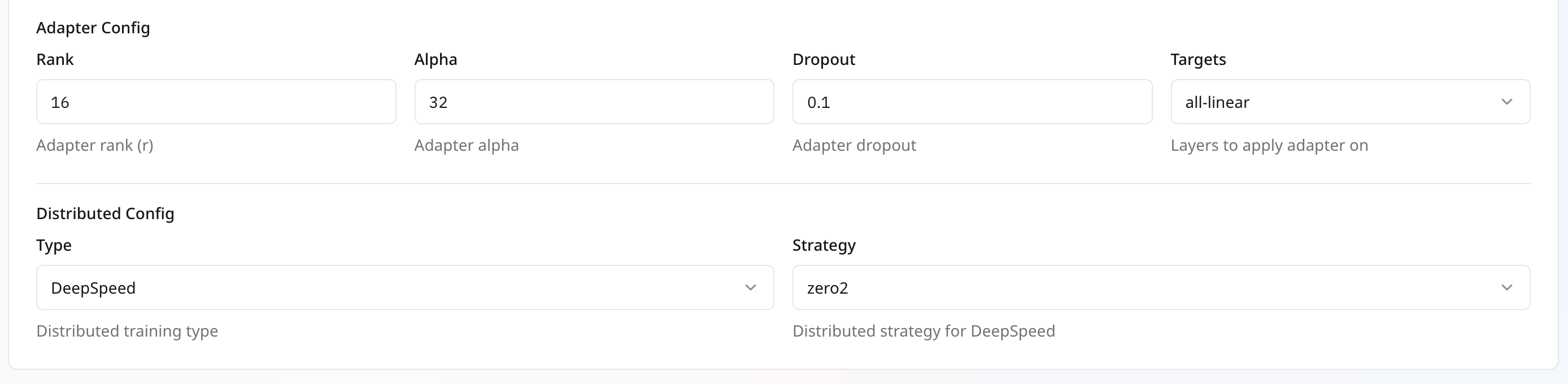
Set Type to DeepSpeed to enable ZeRO optimizations, or DDP for native PyTorch distributed training.
When using DeepSpeed, select the zero3_offload strategy to maximize memory savings by offloading optimizer states to CPU/GPU.