Supported Metrics
The Simplismart metrics endpoint exposes metrics in Prometheus format covering Kubernetes infrastructure health, GPU utilization, inference engine performance, and request lifecycle.For each metric, you only need to provide one of the listed parameters.
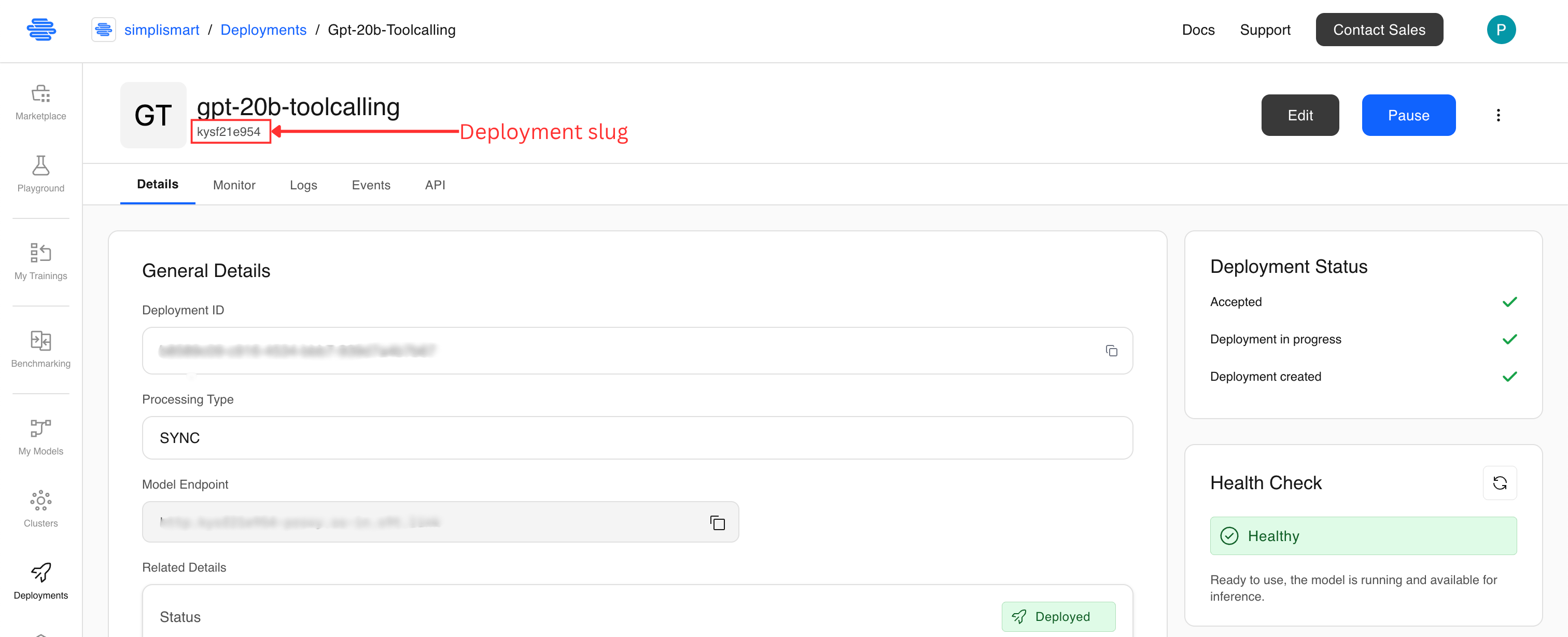
Deployment namespace and deployment slug refer to the same value. Learn how to find it here.
{kind=link}
Kubernetes Deployment Metrics
Track deployment health and replica status.kube_deployment_spec_replicas
The number of desired replicas for a deployment, as specified in the deployment spec.
Type: gauge
Labels:
Deployment namespace (deployment slug).
Deployment name.
kube_deployment_status_replicas
The number of observed replicas for a deployment.
Type: gauge
Labels:
Deployment namespace.
Deployment name.
kube_deployment_status_replicas_available
Number of replicas that are available (ready for at least minReadySeconds).
Type: gauge
Labels:
Deployment namespace.
Deployment name.
kube_deployment_status_replicas_ready
Number of replicas that have passed their readiness probes.
Type: gauge
Labels:
Deployment namespace.
Deployment name.
For inference servers, readiness means “model is loaded and accepting requests.” A container running but not ready consumes resources without serving traffic.
kube_deployment_status_replicas_unavailable
Number of replicas that are not yet available.
Type: gauge
Labels:
Deployment namespace.
Deployment name.
Kubernetes Pod Metrics
Pod-level visibility into lifecycle and health.kube_pod_info
Pod metadata information including node, IP, and phase.
Type: gauge
Labels:
Pod namespace.
Pod name.
Node name where the pod is scheduled.
Pod IP address.
kube_pod_status_phase
Current phase of the pod (Pending, Running, Succeeded, Failed, Unknown).
Type: gauge
Labels:
Pod namespace.
Pod name.
Pod phase (Pending, Running, Succeeded, Failed, Unknown).
kube_pod_container_status_ready
Whether the container is ready (1) or not (0).
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
kube_pod_container_status_running
Whether the container is running (1) or not (0).
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
kube_pod_container_status_restarts_total
Cumulative count of container restarts.
Type: counter
Labels:
Pod namespace.
Pod name.
Container name.
kube_pod_container_status_waiting_reason
The reason the container is in waiting state (e.g., ContainerCreating, CrashLoopBackOff, ErrImagePull).
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
Reason for waiting state.
Container Resource Metrics
Track actual resource consumption.container_cpu_usage_seconds_total
Cumulative CPU time consumed by the container, in core-seconds.
Type: counter
Labels:
Pod namespace.
Pod name.
Container name.
container_memory_working_set_bytes
Current working set memory of the container in bytes. This is what the OOM killer uses for eviction decisions.
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
kube_pod_container_resource_requests
Resource requests configured for the container.
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
Resource type (cpu, memory, nvidia_com_gpu).
Unit of measurement (core, byte, etc.).
kube_pod_container_resource_limits
Resource limits configured for the container.
Type: gauge
Labels:
Pod namespace.
Pod name.
Container name.
Resource type (cpu, memory, nvidia_com_gpu).
Unit of measurement (core, byte, etc.).
GPU Metrics
GPU metrics for Simplismart’s GPU-accelerated inference workloads.DCGM_FI_DEV_GPU_UTIL
GPU utilization as a percentage (0–100). Measures what fraction of time the GPU’s streaming multiprocessors are active.
Type: gauge
Labels:
GPU index.
GPU UUID.
Device identifier.
GPU model name (e.g., “NVIDIA H100”).
Host name.
Deployment namespace.
Pod name.
DCGM_FI_DEV_FB_USED
Frame buffer (GPU VRAM) memory used, in MiB.
Type: gauge
Labels:
GPU index.
Host name.
Deployment namespace.
Pod name.
GPU memory is the primary constraint for model serving. When VRAM is exhausted, inference requests fail with OOM errors.
DCGM_FI_DEV_FB_FREE
Frame buffer (GPU VRAM) memory free, in MiB.
Type: gauge
Labels:
Host name.
Deployment namespace.
Pod name.
Ingress Metrics
External traffic entering the Simplismart platform.nginx_ingress_controller_requests
Total number of requests handled by the NGINX ingress controller.
Type: counter
Labels:
Ingress name.
Namespace.
Service name.
HTTP status code.
HTTP method (GET, POST, etc.).
Request path.
nginx_ingress_controller_requests- Total request countnginx_ingress_controller_request_duration_seconds_bucket- Request duration histogram bucketsnginx_ingress_controller_request_duration_seconds_sum- Total request duration sumnginx_ingress_controller_request_duration_seconds_count- Total request count for duration
nginx_ingress_controller_request_duration_seconds
End-to-end request duration as observed by the ingress controller.
Type: histogram (exposes _bucket, _sum, and _count time series)
Labels:
Ingress name.
Namespace.
Service name.
HTTP status code.
HTTP method (GET, POST, etc.).
Request path.