- Navigate to the My Trainings section in the platform.
- Click on Add a Training Job to create a new job.
Basic Details and Dataset Upload
- Provide a name for your experiment.
- Upload your training dataset.
Data Requirements for Training
Data Requirements for Training
- Prepare the Training Dataset
- Compile all the images to be used for training into a single folder.
- Text Files for Images (optional)
- Each image in the training dataset can have an accompanying
.txtfile with the same name. - The
.txtfile should contain a description detailing what is required in the corresponding image. This step will significantly enhance the effectiveness of the training process
- Each image in the training dataset can have an accompanying
- Packaging Files in a ZIP
- All images and their respective
.txtfiles must be included in a single ZIP file. - Ensuring both image and text files are packaged together improves the quality of the training process.
- All images and their respective
- Trigger Word Assignment
- Assign one unique trigger word per training job.
- This trigger word will be used to reference the LoRA generated by the training job.
Upload the training dataset as a file containing the required images for model training. This ensures that all files are placed at the root of the zip archive, with no subdirectories considered.
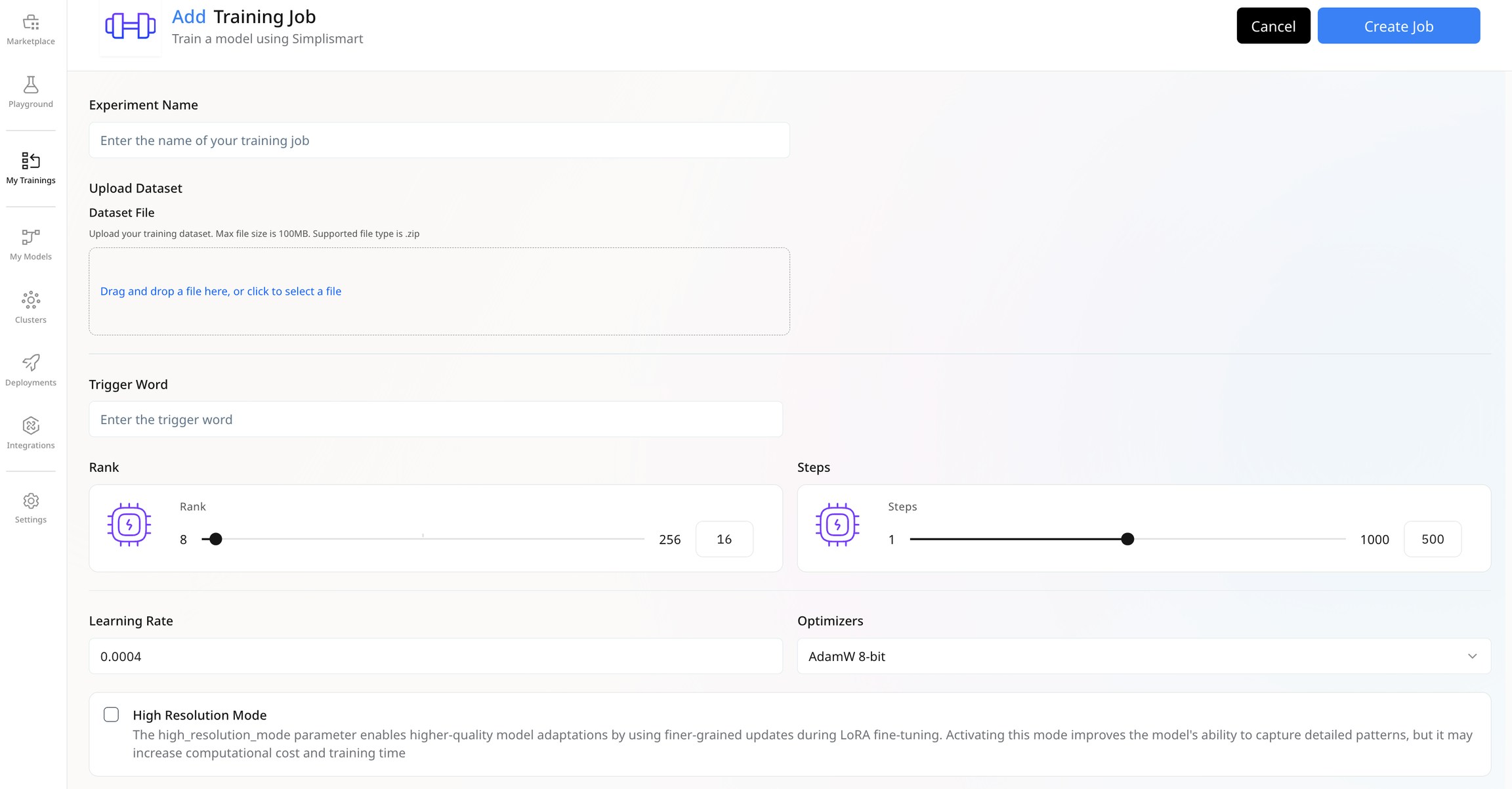
Select Training Parameters
Update the training parameters based on your requirements for the training job. Here is a short explanation of these parameters:- Specifies a keyword or phrase that activates a specific behaviour in the model during inference. It enables the model to adjust its responses based on the context or task without requiring further training.
- Controls the dimensionality of the LoRA matrices; a higher rank improves adaptation but increases computational cost.
- Defines the number of fine-tuning iterations; more steps improve model performance but increase training time.
- Controls the size of weight updates during fine-tuning. A higher value accelerates training but may risk overshooting, while a lower value offers more precise updates at the cost of longer training time.
- Controls how the model’s parameters are updated during training to minimize loss.
- AdamW 8-bit: A variant of the Adam optimizer that leverages 8-bit precision to optimize memory usage and increase computational speed. This approach is ideal for large-scale models enabling quicker convergence while preserving model stability and high performance.
- Prodigy:A custom-built optimizer engineered to boost training speed and model efficiency. It accelerates the convergence process and ensures optimal performance, making it suitable for both fine-tuning and large-scale model training.